Souvent méconnues, les fonctions analytiques ou fonctions de fenêtrage permettent d’effectuer facilement des requêtes SQL complexes à écrire autrement. Nous vous proposons de passer en revue les grands principes de ces fonctions, à partir de quelques exemples pratiques.
- Présentation générale
- ROW_NUMBER()
- SUM(), AVG(), COUNT(), MAX(), MIN()
- Exemple 1: Total des ventes par région
- Exemple 2: Contribution d’un produit dans la région
- RANK()
- LAG() et LEAD()
- Utilisation de la fonction LAG()
- Utilisation de la fonction LEAD()
- Astuce pour la détection de doublons dans une table
- Conclusion
Présentation générale
Les fonctions analytiques ou fonctions de fenêtrage sont incontournables dans le monde de la Business Intelligence. Elles permettent d’effectuer des calculs analytiques avancés tout en conservant le détail ligne par ligne, ce que ne permettent pas les agrégations effectuées avec la clause GROUP BY. Elles permettent d’effectuer des calculs sur un ensemble de lignes associées à la ligne courante, tout en conservant le détail de chaque ligne dans le résultat. Elles sont couramment utilisées pour des calculs tels que les agrégats, les classements et les totaux cumulés.
La syntaxe générale est la suivante :
SELECT Colonne,
FONCTION_FENETRE (colonne2) OVER ([PARTITION BY colonne3] [ORDER BY colonne4])
FROM table;
La clause OVER définit la « fenêtre » de lignes sur laquelle le calcul est effectué. Elle permet de :
- Diviser les données en groupes logiques (PARTITION BY)
- Définir l’ordre des lignes à l’intérieur de chaque groupe (ORDER BY)
On peut ainsi grâce à la clause OVER, appliquer les fonctions comme SUM, AVG, COUNT, MAX, MIN, ROW_NUMBER, RANK… tout en conservant le niveau de granularité le plus fin.
Dans cet article, nous revenons sur quelques usages essentiels, illustrés avec des exemples concrets issus du quotidien d’un analyste BI. Les requêtes ci-dessous ont été exécutées sur une base de données Microsoft SQL Server, néanmoins la syntaxe sera la même sur tout type de base de données respectant la norme SQL:2003.
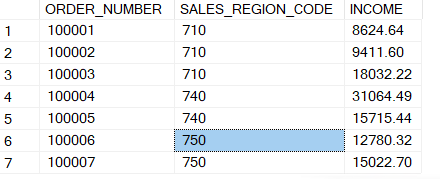
Appuyons nous sur les données de ventes suivantes :
ROW_NUMBER()
Numérote les lignes dans chaque partition.
SELECT ORDER_NUMBER,
SALES_REGION_CODE,
INCOME,
ROW_NUMBER() OVER (PARTITION BY SALES_REGION_CODE ORDER BY ORDER_NUMBER) AS row_number
FROM dbo.RESUME_GOSALES;
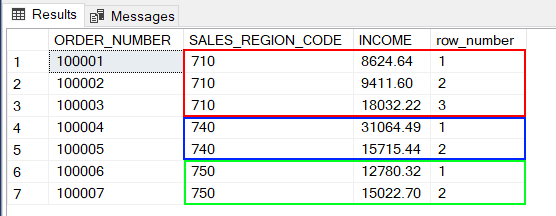
On numérote chaque ligne de commande à l’intérieur de chaque région en fonction du numéro de commande.
SUM(), AVG(), COUNT(), MAX(), MIN()
Exemple 1: Total des ventes par région
SELECT ORDER_NUMBER,
SALES_REGION_CODE,
INCOME,
SUM(INCOME) OVER (PARTITION BY SALES_REGION_CODE) AS TotalByRegion
FROM dbo.RESUME_GOSALES;
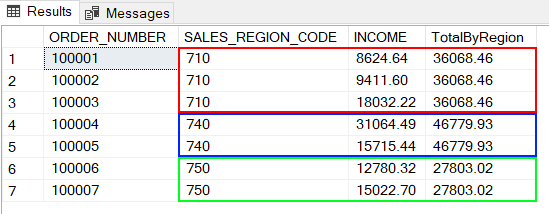
On arrive à calculer le total des ventes par région sans avoir à agréger les lignes.
- Pour la région 710 : 8624,64 + 9411,6 + 18032,22 = 36068,46
- Pour la région 740 : 31064 + 15715,44 = 46779,93
- Pour la région 750 : 12780,32 + 15022,7 = 27803,02
Exemple 2: Contribution d’un produit dans la région
SELECT ORDER_NUMBER,
SALES_REGION_CODE,
INCOME,
INCOME * 1.0 / SUM(INCOME) OVER (PARTITION BY SALES_REGION_CODE) AS ContributionPct
FROM dbo.RESUME_GOSALES;
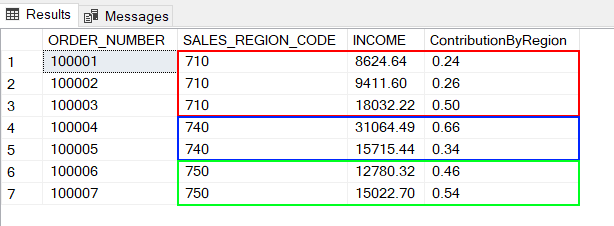
La commande 100003 représente 50% des revenus dans la région 710.
RANK()
SELECT ORDER_NUMBER,
SALES_REGION_CODE,
COUNTRY_CODE,
INCOME,
RANK() OVER(PARTITION BY SALES_REGION_CODE ORDER BY INCOME DESC) AS RankInRegion
FROM dbo.RESUME_GOSALES;
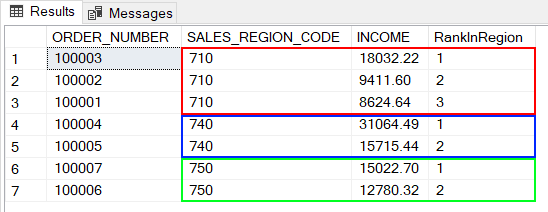
On attribue un classement à l’intérieur de chaque département en fonction du montant des ventes. Dans la région 710 par exemple, c’est la commande 100003 qui représente le revenu le plus élevé.
LAG() et LEAD()
LAG et LEAD sont des fonctions fenêtres qui permettent d’accéder à une valeur d’une autre ligne. Les deux fonctions ont fondamentalement la même syntaxe ; il suffit de changer le nom de la fonction.
Syntaxe générale :
LAG(COLONNE, OFFSET, VALEUR_PAR_DEFAUT) OVER (PARTITION BY COLONNE_PARTITION ORDER BY COLONNE_ORDRE)
On accède ainsi à la ligne qui est à offset (décalage physique) lignes avant (ou après) la ligne actuelle dans la partition. La valeur par défaut du décalage est 1.
LAG : Valeur de la ligne précédente
LEAD : Valeur de la ligne suivante
Lag() et lead() sont très utilisés pour comparer des valeurs dans le temps et calculer des évolutions.
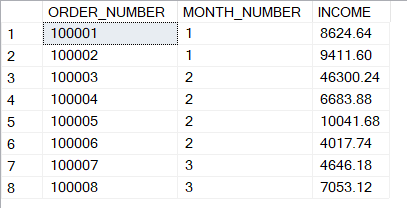
Pour illustrer ces deux fonctions, considérons les données suivantes :
Utilisation de la fonction LAG()
SELECT ORDER_NUMBER,
MONTH_NUMBER,
INCOME,
LAG(INCOME,1) OVER (ORDER BY MONTH_NUMBER) AS PreviousMonthIncome,
INCOME - LAG(INCOME,1) OVER (ORDER BY MONTH_NUMBER) AS Variation
FROM dbo.RESUME_GOSALES;
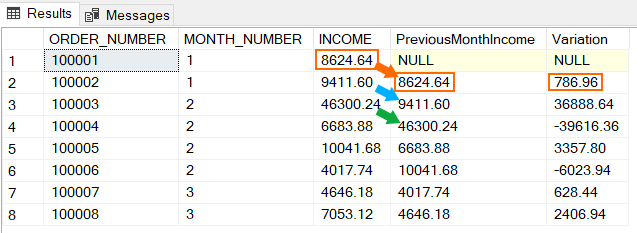
PreviousMonthIncome : Pour la première ligne, il n’existe pas de ligne précédente d’où la valeur par défaut NULL. Vous pouvez néanmoins personnaliser cette valeur par défaut en utilisant le paramètre VALEUR_PAR_DEFAUT de la fonction. Pour la seconde ligne, on obtient 8624,64 qui est le revenu de la première ligne (ligne précédente) ; ainsi de suite.
Variation : variation = ligne actuelle – ligne précédente. Pour la première ligne, vu qu’il n’existe pas de ligne précédente, la variation est nulle. Pour la seconde ligne, la variation vaut 9411,60 – 8624,64 = 786,96.
Utilisation de la fonction LEAD()
SELECT ORDER_NUMBER,
MONTH_NUMBER,
INCOME,
LEAD(INCOME,1) OVER (ORDER BY ORDER_NUMBER) AS NextMonthIncome
FROM dbo.RESUME_GOSALES;
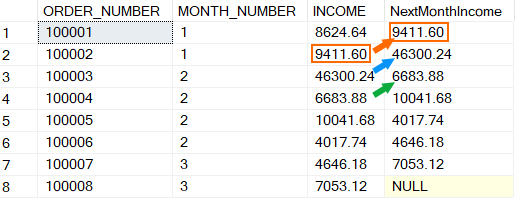
NextMonthIncome : Pour la première ligne, on obtient 9411,60 qui est le revenu de la deuxième ligne (ligne suivante) ; ainsi de suite. Pour la dernière ligne, il n’existe pas de ligne suivante d’où la valeur NULL (ou tout autre valeur par défaut que vous aurez choisi).
Somme cumulée
SELECT ORDER_NUMBER,
MONTH_NUMBER,
INCOME,
SUM(INCOME) OVER (ORDER BY MONTH_NUMBER) AS CumulativeIncome
FROM dbo.RESUME_GOSALES;
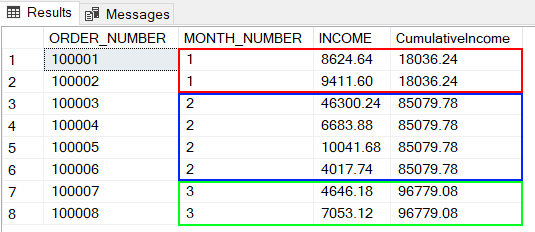
- Au premier mois, le cumul = somme de toutes les lignes du mois = 18036,24.
- Au second mois, le cumul = cumul du premier mois + toutes les lignes du deuxième mois) = 18036,24 + 46300,24 + 6683,88 + 10041,68 + 4017,74 = 85079,08.
Astuce pour la détection de doublons dans une table
Classiquement, on détecte les doublons avec une requête du type :
SELECT CLE_METIER,
COUNT(*)
FROM MA_TABLE
GROUP BY CLE_METIER
HAVING COUNT(*) > 1;
Problème : A cause du GROUP BY, on perd le détail des lignes donc impossible de voir pourquoi il y a doublon. Par conséquent, le résultat est inexploitable pour l’analyse métier.
Solution avec fonction analytique: Les fonctions analytiques permettent de détecter les doublons, de conserver toutes les colonnes afin d’analyser visuellement et plus facilement la cause du doublonnage.
Le principe: Calculer le nombre d’occurrences par clé métier (sans regrouper les lignes) avec COUNT(*) OVER (PARTITION BY cle_metier)
Supposons les données clients suivantes :
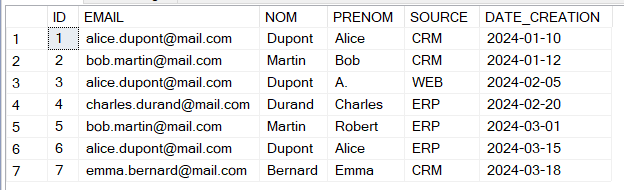
La clé métier étant l’adresse email, nous pouvons voir qu’il existe des doublons dans cette table.
La requête suivante permet de déterminer et analyser les doublons est la suivante:
SELECT CLIENTS.*,
COUNT(*) OVER (PARTITION BY EMAIL) AS NB_OCCURRENCES
FROM CLIENTS;
Vous pouvez filtrer pour ressortir uniquement les doublons :
SELECT *
FROM (
SELECT CLIENTS.*,
COUNT(*) OVER (PARTITION BY EMAIL) AS NB_OCCURRENCES -- Calcule le nombre d'occurrences
FROM CLIENTS
) t
WHERE NB_OCCURRENCES > 1 -- Ramène uniquement les lignes concernés par les doublons
ORDER BY EMAIL, DATE_CREATION;
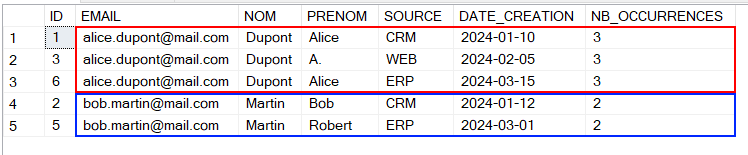
On obtient toutes les lignes en doublon, avec leurs valeurs complètes, leur ordre de création et une vision immédiate des différences entre les lignes (nom, date, source, etc.). Ceci est idéal pour analyser la qualité de données et debugger.
Conclusion
Les fonctions analytiques sont indispensables pour produire des résultats avancés tout en conservant la granularité des données. Bien maîtrisées, elles simplifient le SQL et améliorent la lisibilité des traitements.