Derrière ce mot de plus en plus entendu et souvent indéfini se cachent un ensemble de concepts et d’architectures de données bien précis qu’il importe de bien comprendre à l’heure où les besoins d’interconnexion entre systèmes explosent. Cet article va tenter de démystifier cela !
Pourquoi un Data Hub ?
L’utilisation de plusieurs technologies et applications implique la formation des silos de données qui ne sont pas connectés entre eux, ce qui génère plusieurs problèmes : duplication et redondance des enregistrements, nombre de flux important pour interconnecter les applications, etc… Des solutions traditionnelles basées sur une communication asynchrone ont déjà essayé de répondre à cette problématique, vue les implications de ce type de connexion, l’apport de ces solutions reste limité en termes de performance.
Le Data Hub permet de regrouper et centraliser les silos de données d’un système d’information dans un référentiel central. Il permet, d’une part, de fournir aux composants applicatifs du système d’information un accès aux données d’une façon simple et rapide, d’autre part, il permet d’appliquer des analyses avancées sur les données de l’entreprise pour en tirer de la valeur. L’objectif d’un Data Hub est de gérer et orchestrer les échanges de données en temps réel entre les composants d’un système d’information.
Quel est son apport ?
Le Data Hub est souvent confondu avec le Data Lake ou le Data Warehouse, le Data Lake est une architecture utilisée dans le domaine de la Big Data elle peut être rapprochée à un ODS, il permet de remédier au problème des silos de données en regroupant toutes les données de l’entreprise dans un point de stockage, l’objectif du Data Lake est de fournir un accès unique et séparé des systèmes de production pour des fins d’analyse, contrairement à un Data Hub le Data Lake stocke les données dans leurs formats natifs sans indexation ou harmonisation.
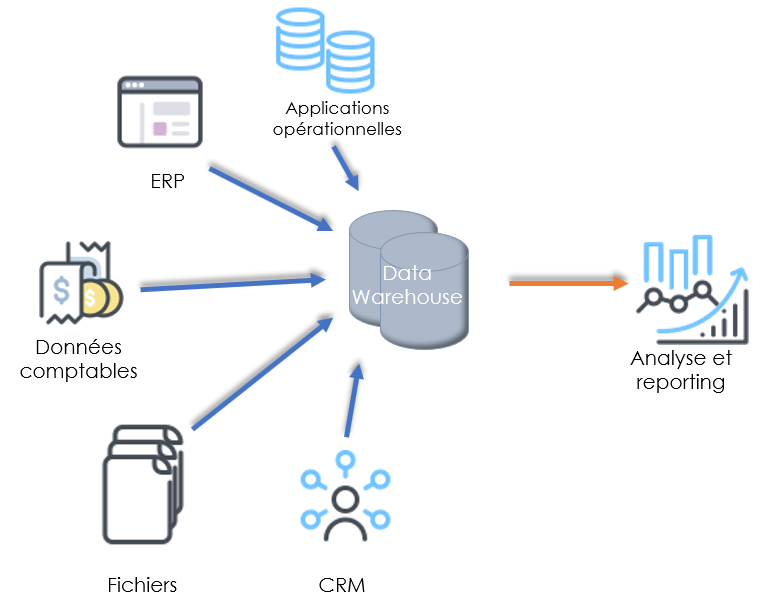
D’autre part, le Data Warehouse est une architecture unidirectionnelle (des bases de données opérationnelles vers les bases de données décisionnelles) qui met à disposition des décideurs des données transformées, agrégées et historisées. Les données du Data Warehouse sont souvent traitées de manière asynchrone. Ce type d’architecture est utilisé pour créer des rapports décisionnels, il est alors considéré comme le cœur de la Business Intelligence.
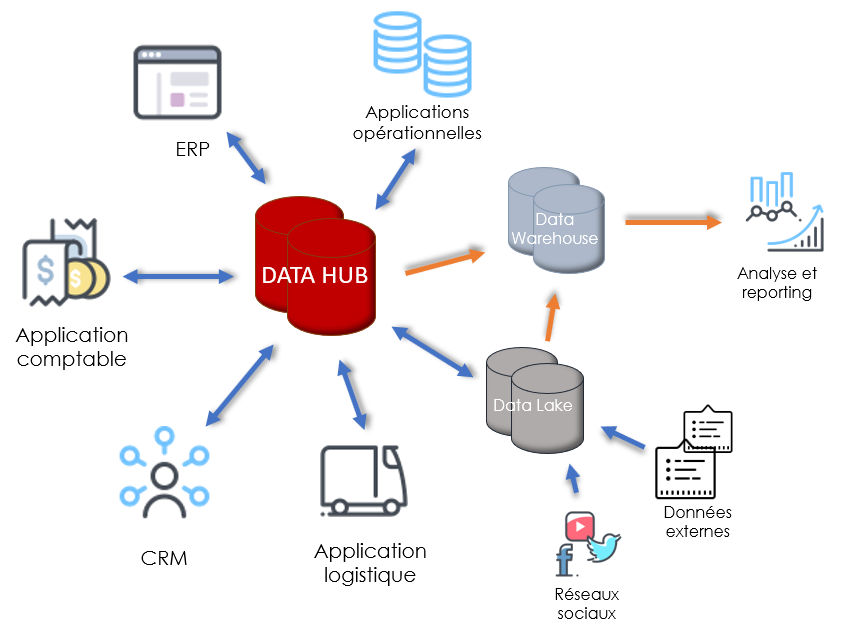
En revanche, un Data Hub est une architecture qui complète les limites du Data Lake et du Data Warehouse. Avec un data hub, l’entreprise peut analyser, en plus des données opérationnelles, des données externes et complémentaires issues de nombreuses sources comme les objets connectés, les réseaux sociaux ou les statistiques, cela permet d’effectuer des analyses plus poussées comme l’échantillonnage ou les analyses prédictives. De plus, un data hub intègre des modèles de contrôle de données et de traçabilité, ces modèles assurent en temps réel la qualité et l’intégrité des données échangées, ils permettent également de donner une vision claire sur la provenance des données et les transformations qu’elles ont subies.
Pourquoi construire un Data Hub ?
Le Data Hub repose sur trois principes fondamentaux : le stockage, l’harmonisation et l’indexation.
Stockage
les données de l’entreprise sont copiées et regroupées dans un nouvel espace de stockage, cela permet, dans un premier temps, de libérer la structure du data hub des bases de données opérationnelles et d’augmenter la disponibilité des données, le stockage permet également de rassembler les silos de données en une source unique.
Harmonisation
les données des silos proviennent de diverses applications, elles sont saisies à l’aide de différentes technologies et stockées selon des formats et des architectures différentes, il est alors important que ces données soient harmonisées pour pouvoir utiliser et analyser l’ensemble des données d’un système d’information. L’harmonisation peut être divisée en plusieurs catégories :
- le premier type est l’harmonisation de structure, les données des clients peuvent exister dans plusieurs bases de données, parfois stockées dans une seule table et d’autres fois dans une structure de table, l’harmonisation de structure consiste à gérer ces différences de structures pour que les données soient utilisables de façon homogène.
- Le deuxième type est l’harmonisation de nomenclature, il consiste à gérer les silos qui stockent la même information mais selon des noms de table ou de colonne différents.
- Le dernier type a pour objectif d’harmoniser les informations qui présentent des différences sémantiques, par exemple, le statut d’une commande dans un premier silo peut avoir comme valeur {en attente d’acceptation, accepté, en cours de préparation, expédié, en cours de livraison, reçu} dans un autre silos le statut sera {en attente, traité, préparé, expédié}, il est important d’établir les relations de mapping entre ces données pour pouvoir analyser les commandes de l’ensemble des silos.
Indexation
c’est le troisième principe de l’architecture data hub, l’indexation permet d’effectuer des recherches et des analyses plus rapides sur les données indexées. Cette opération ne peut être appliquée que sur les données stockées et harmonisées. Dans leurs formats natifs, les données ne peuvent pas être indexées car une donnée peut exister dans plusieurs silos selon des formats différents et avec des valeurs incohérentes.
Quels sont les gains d’un Data Hub ?
Ce tableau récapitule les points communs et les différences entre les data hub, data lake et les data warehouse :
| Data Hub | Data Lake | Data Warehouse | |
| Objectif | Partager les données | Stocker les données | Analyser les données |
| Quelles sont les données concernées ? | Données de l’entreprise + données externes pour enrichir les analyses | Toutes les données de l’entreprise | Données à analyser, issues des applications opérationnelles |
| Les données sont-elles stockées ? | Oui | Oui | Oui |
| Les données sont-elles traitées ? | Les données sont harmonisées et indexées | Non, les données restent dans leur format brut | Oui, les données sont transformées et agrégées |
| Indexation | Les données sont indexées pour accélérer la recherche et l’analyse | Pas d’indexation | Certaines données peuvent être indexées pour diminuer le temps de réponse des requêtes |
| Qualité des données | Haute qualité garantie par une gouvernance en temps réel | Qualité non garantie : données brutes et de formats différents | Données triées et nettoyées prêtes pour une utilisation BI |
| Coût | Coût de mise en place moins important | Coût de stockage faible | Coût d’implémentation et de stockage important |
| Utilisateurs | Data Scientists, Business Analysts, métiers | Data Scientists, développeurs | Business Analysts, métiers |
| Volume / Performance | Le volume n’affecte pas la performance | Le volume n’affecte pas la performance | Le volume peut affecter la performance |
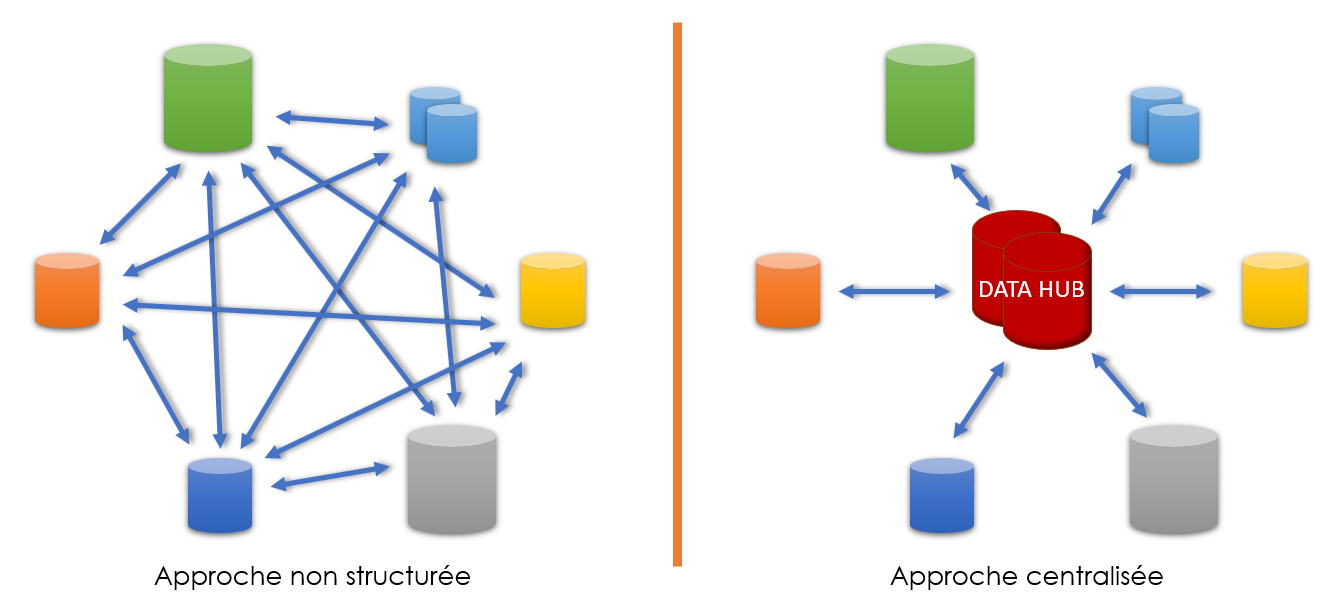
Les architectures traditionnelles qui reposent sur des connexions point à point (P2P) sont plus couteux et leur architecture est souvent complexe. Afin d’interconnecter 10 logiciels et leur permettre d’échanger les données entre eux il va falloir établir plus de 40 connexions point à point. Même en optant pour une solution ESB l’architecture reste encore trop lourde et peu flexible, à cause de l’architecture bus qui limite le TPS (transaction par seconde), en plus, l’ESB exige d’adapter et standardiser les formats de données des systèmes pour pouvoir communiquer les données entre eux.
Le Data Hub permet d’interconnecter les systèmes d’une entreprise en utilisant une seule connexion par système, cela réduit sensiblement le cout de maintenance d’une telle architecture et permet de gagner en agilité. Lorsque l’entreprise souhaite effectuer une migration d’un systeme ou d’un outil, en utilisant une technologie ESB ou P2P, il va falloir mettre à jour tous les points d’entrée et de sortie de ce système, en revanche, l’impact de cette migration sera plus restreint dans le cas d’une architecture data hub.
L’un des principaux avantages du data hub réside dans sa gestion des données.
D’un côté, il permet de gérer les données de l’entreprise à l’aide des processus mise en place pour traiter les données en temps réel et garantir la qualité des données échangées. D’autre part, il permet d’identifier les données de l’entreprise afin d’assurer l’unicité des données traitées.
Normalement une base de données utilise des clés internes pour identifier les données, comme les clients ou les produits. Dès que le référentiel produit ou clients existe dans plusieurs systèmes, un même produit ou client peut avoir différentes clés selon la base de données, le data hub permet de pallier ce problème en créant des clés universelles pour chaque élément du référentiel. Il supplée en cela la mise en œuvre d’une solution MDM (Master Data Management).
En général, le data hub repose sur l’architecture ‘Hub and Spokes’, cette architecture est similaire au modèle en étoile, le ‘Hub’ est l’élément qui centralise les données de l’entreprise, il permet de faciliter et orchestrer les échanges entre les applications, les ‘Spokes’ sont les applications reliées au ‘Hub’ qui interviennent pour partager leurs données avec les autres composants ou pour accéder aux données des autres applications.
Le Data Hub n’est donc pas qu’une base de données qui regroupe toutes les données d’une entreprise. C’est plutôt une architecture permettant d’identifier la relation entre des données provenant de sources multiples, de gérer des données d’entreprise et les rendre cohérentes afin de créer un système de données centralisé qui peut être utilisé par l’ensemble des applications de l’entreprise.