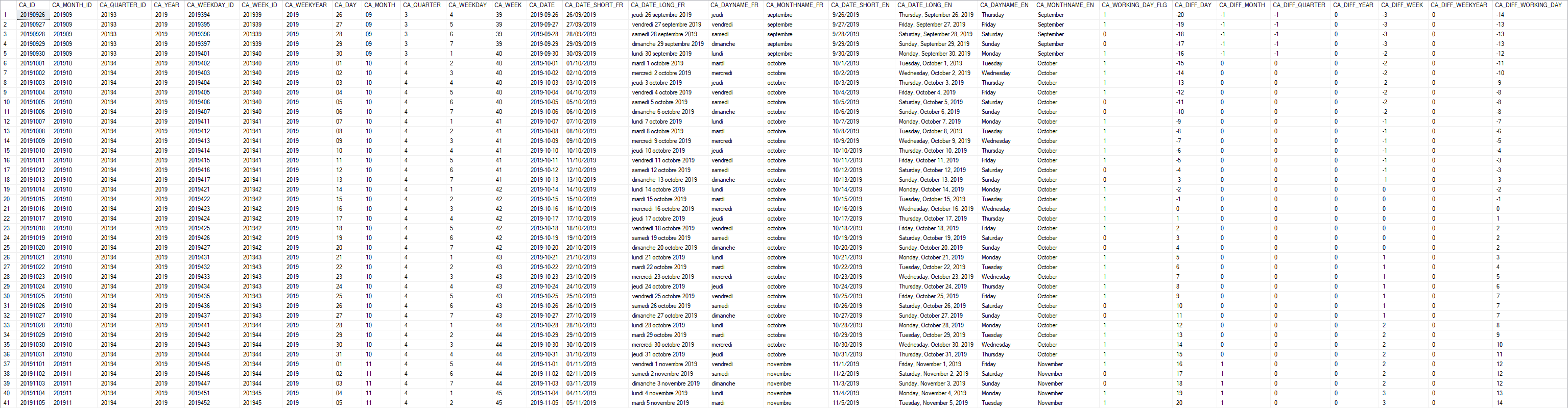
Comment modéliser une bonne dimension temps ? C’est ce que nous allons voir dans cet article, à travers quelques bonnes pratiques et astuces de modélisation, puis un exemple de mise en œuvre sous Microsoft SQL Server.
Sommaire
- Sommaire
- Modélisation de la dimension
- Les niveaux de la dimension temps
- Informations stockées
- Identifiants
- Astuce #1 : Les champs différentiels
- Astuce #2 : Les jours ouvrés
- Mise en pratique
Dans la construction d’un datawarehouse, la dimension temps joue en effet un rôle à part des autres axes d’analyse, car les nombreuses analyses temporelles demandées par les utilisateurs (Consolidations à date, comparaisons avec la semaine ou l’année précédente, etc…) peuvent être relativement complexes à modéliser dans un cadre relationnel (SQL).
Avec une bonne conception de la dimension temps il est cependant possible de simplifier les requêtes liées à ces analyses, pour assurer leur bonne performance et faciliter la modélisation des rapports.
Modélisation de la dimension
Les niveaux de la dimension temps
Les différents niveaux classiques d’une dimension temps peuvent être décrits de la manière suivante :
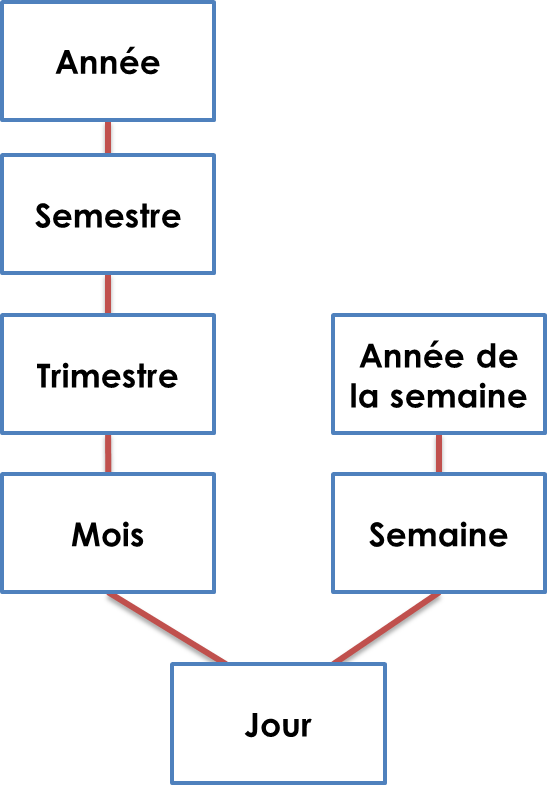
Il faut noter les subtilités suivantes :
- Les semaines et les mois ne sont pas regroupables dans une même hiérarchie. En effet, un mois contient plusieurs semaines, mais une semaine peut-être à cheval sur plusieurs mois il n’y a donc pas une cardinalité « 1⇔n » entre les deux notions mais une cardinalité « n⇔n ».
- Si l’on se réfère à la numérotation ISO des semaines communément appliquée en entreprise, on constate que l’année de rattachement d’une semaine n’est pas tout le temps la même que l’année des jours qu’elle contient. La plupart du temps lors du changement d’année, la 52e ou 53e semaine de l’année précédente, ou la 1ère semaine de la nouvelle année est à cheval sur les deux années. Par exemple lors du passage de 2015 à 2016 :
| Date | Jour | Semaine | Année de la semaine |
|---|---|---|---|
| 01/01/2016 | Vendredi | 53 | 2015 |
| 02/01/2016 | Samedi | 53 | 2015 |
| 03/01/2016 | Dimanche | 53 | 2015 |
| 04/01/2016 | Lundi | 01 | 2016 |
| 05/01/2016 | Mardi | 01 | 2016 |
| 06/01/2016 | Mercredi | 01 | 2016 |
| 07/01/2016 | Jeudi | 01 | 2016 |
Il faut donc distinguer deux informations d’année : l’année calendaire, et l’année de la semaine.
Informations stockées
Pour chaque niveau, et pour faciliter le reporting, il est préférable de stocker directement dans la dimension temps toutes les informations qui seront jugées nécessaires, de sorte à les avoir à disposition et éviter ainsi les calculs supplémentaires. Dans la mise en place proposée, nous stockerons les éléments classiques suivants :
- Année calendaire
- N° du semestre (1-2)
- N° du trimestre (1-4)
- N° du mois (1-12)
- N° du jour dans le mois (1-31)
- N° du jour dans l’année (1-366)
- Année de la semaine
- N° du jour dans la semaine (1-7)
- N° de la semaine (1-53)
- Nom du mois (Janvier-Décembre), en anglais et en français
- Nom du jour (Lundi-dimanche), en anglais et en français
- Date courte formatée, en anglais et en français
- Date longue formatée, en anglais et en français
Identifiants
A ces éléments nous devons aussi ajouter un identifiant unique pour chaque niveau, qui permettra facilement d’opérer des consolidations (agrégations) et des tris lors du reporting. Plutôt que des identifiants incrémentaux qui rendrait les données compliquées à lire, il est préférable de les construire à partir de la date. Cela a l’immense avantage de rendre ces identifiants prédictibles et simples à relire. On obtient pour chaque niveau les identifiants suivants :
| Niveau | Expression |
|---|---|
| Jour | [Année calendaire] * 10000 + [N° du mois] * 100 + [N° du jour dans le mois] |
| Mois | [Année calendaire] * 100 + [N° du mois] |
| Trimestre | [Année calendaire] * 100 + [N° du trimestre] |
| Semestre | [Année calendaire] * 100 + [N° du semestre] |
| Année | [Année calendaire] |
| Semaine | [Année de la semaine] * 100 + [N° de la semaine] |
| Année de la semaine | [Année de la semaine] |
En plus de ces champs de bases, nous allons ensuite ajouter des champs supplémentaires qui simplifieront grandement certains calculs souvent demandés dans le cadre du reporting.
Astuce #1 : Les champs différentiels
Une problématique qui revient régulièrement est la construction de rapports dits « À date », pour lesquels on souhaite que le périmètre temporel s’adapte au jour de l’exécution du rapport.
Par exemple, si on souhaite réaliser un rapport présentant le chiffre d’affaire de la veille, on peut être tenté de réaliser une requête filtrée avec une date « en dur », néanmoins on sera obligé dans ce cas de mettre à jour manuellement cette date dans le rapport tous les jours, ce qui est loin d’être pratique, notamment dès que l’on souhaitera automatiser l’exécution du rapport.
De plus, qu’en est-il de filtrages « à date » plus complexes et tout aussi classiques ? Par exemple « les six dernières semaines glissantes » ou encore « l’année à date » ? D’autant plus que les indicateurs sont souvent à comparer entre eux, comme par exemple « Année en cours » vs « Année – 1 », ce qui démultiplie le nombre de requêtes à effectuer.
A la place, il faudrait pouvoir écrire un filtre dont l’expression ne dépend pas du jour d’exécution. C’est possible en considérant que ce qui est important c’est que l’on souhaite les données de la veille, c’est-à-dire 1 jour avant aujourd’hui.
Par exemple avec SQL Server, le filtre à mettre en place serait : « CA_DATE = GETDATE() - 1GETDATE() est la fonction donnant le jour au moment de l’exécution du rapport. Ainsi à chaque exécution le filtre est calculé par rapport au jour d’exécution.
Mais en imaginant des filtres plus complexes, on tombe assez vite sur des formules de transformation de dates compliquées, rigides et assez peu lisibles, donc difficiles à maintenir.
De plus avec une formule comme l’exemple ci-dessus, la fonction GETDATE() est calculée à chaque exécution, le résultat d’un rapport donc devient dépendant du jour d’exécution, ce qui n’est pas souhaitable car cela peut provoquer des inconsistances (Même rapport, même paramètres utilisateurs, et résultats différents suivant la date d’exécution).
Cette première astuce consiste donc à stocker dans la dimension la différence en jours entre n’importe quel jour de la dimension et aujourd’hui. Par exemple, en supposant que nous soyons le 15/10/2019, on obtient pour ce champ :
| Date | Différentiel vs Aujourd’hui |
|---|---|
| … | |
| 10/10/2019 | -5 |
| 11/10/2019 | -4 |
| 12/10/2019 | -3 |
| 13/10/2019 | -2 |
| 14/10/2019 | -1 |
| 15/10/2019 | 0 |
| 16/10/2019 | 1 |
| 17/10/2019 | 2 |
| 18/10/2019 | 3 |
| 19/10/2019 | 4 |
| 20/10/2019 | 5 |
| … |
Bien sûr pour que cela fonctionne, il faut que ce calcul différentiel soit rafraîchi en même temps que le datawarehouse, pour mettre à jour l’information dans la dimension. Ainsi avec un rafraichissement le 16/10/2019, et une fois les données recalculées on obtiendra :
| Date | Différentiel vs Aujourd’hui |
|---|---|
| … | |
| 10/10/2019 | -6 |
| 11/10/2019 | -5 |
| 12/10/2019 | -4 |
| 13/10/2019 | -3 |
| 14/10/2019 | -2 |
| 15/10/2019 | -1 |
| 16/10/2019 | 0 |
| 17/10/2019 | 1 |
| 18/10/2019 | 2 |
| 19/10/2019 | 3 |
| 20/10/2019 | 4 |
| … |
Si l’on reprend l’exemple d’un rapport donnant le chiffre d’affaire de la veille, avec ce champ différentiel, il suffit alors de filtrer sur la valeur -1.
Ce qui est vrai pour les dates est aussi vrai pour les autres niveaux de la dimension. Il est donc possible aussi de stocker de la même manière la différence de chaque mois par rapport au mois en cours, de chaque année par rapport à l’année en cours, etc…
Le stockage dans la dimension temps de ces informations différentielles présente un deuxième avantage, il permet aussi de simplifier la réalisation d’indicateurs de durées : En soustrayant la valeur différentielle ainsi stockée (en jour, en mois ou en semaines) entre deux dates, on obtient la durée souhaitée, dans l’unité souhaitée, et ce quel que soit le jour d’exécution.
Par exemple si nous sommes le 15/10/2019, cela donne :
[17/10/2019] - [10/10/2019] = [2] - [-5] = 7 jours
Même après rafraichissement des données le 16/10/2019 :
[17/10/2019] - [10/10/2019] = [1] - [-6] = 7 jours
Astuce #2 : Les jours ouvrés
En complément de l’astuce précédente, une demande fréquente en terme de reporting consiste à demander les même choses, mais sur une base de jours ouvrés pour l’entreprise.
À partir de l’exemple précédent, il ne s’agirait plus alors de demander au rapport les données de la veille, mais les données du dernier jour ouvré. Or ce calendrier de jours ouvrés est différent dans chaque entreprise et qu’il n’existe aucune fonction native dans quel que langage que ce soit permettant d’obtenir la durée entre deux dates, exprimée en jours ouvrées.
Par exemple, dans Microsoft SQL Server la fonction GETDATE() donne la date du jour, mais il n’est pas possible de lui soustraire directement un jour ouvré.
Pour résoudre cette complexité, nous allons ajouter deux champs dans notre dimension temps :
Le premier est un champ de type « vrai/faux » permettant de taguer un jour comme ouvré/non ouvré. Le champ doit être alimenté avec le calendrier de jours ouvrés spécifique à l’entreprise.
Pour les besoins de l’exemple nous définirons les jours ouvrés avec une règle assez simple : les jours seront ouvrés du lundi au vendredi, et fériés les samedis et dimanches.
Ainsi, avec un tel calendrier on obtient pour ce champ :
| Jour | Date | Jour ouvré |
|---|---|---|
| … | ||
| jeudi | 10/10/2019 | 1 |
| vendredi | 11/10/2019 | 1 |
| samedi | 12/10/2019 | 0 |
| dimanche | 13/10/2019 | 0 |
| lundi | 14/10/2019 | 1 |
| mardi | 15/10/2019 | 1 |
| mercredi | 16/10/2019 | 1 |
| jeudi | 17/10/2019 | 1 |
| vendredi | 18/10/2019 | 1 |
| samedi | 19/10/2019 | 0 |
| dimanche | 20/10/2019 | 0 |
| … |
De cette manière, on peut déjà aisément filtrer les jours ouvrés et non-ouvrés.
Le deuxième champ est un champ différentiel, comme vu dans l’astuce précédente, qui va stocker la différence en jours ouvrés entre un jour de la table et aujourd’hui.
Si nous sommes le 15/10/2019, cela donne :
| Jour | Date | Jour ouvré | Diff. jours ouvrés |
|---|---|---|---|
| … | |||
| jeudi | 10/10/2019 | 1 | -3 |
| vendredi | 11/10/2019 | 1 | -2 |
| samedi | 12/10/2019 | 0 | -2 |
| dimanche | 13/10/2019 | 0 | -2 |
| lundi | 14/10/2019 | 1 | -1 |
| mardi | 15/10/2019 | 1 | 0 |
| mercredi | 16/10/2019 | 1 | 1 |
| jeudi | 17/10/2019 | 1 | 2 |
| vendredi | 18/10/2019 | 1 | 3 |
| samedi | 19/10/2019 | 0 | 3 |
| dimanche | 20/10/2019 | 0 | 3 |
| … |
Notez que l’indicateur ne s’incrémente pas sur un jour non ouvré. Le 12/10/2019 et le 13/10/2019 se retrouvent comme le 11/10/2019, à 2 jours ouvrés du 15/10/2019.
Ainsi, dans un rapport si l’on filtre sur cet indicateur avec la valeur -2, les données du samedi et du dimanche seront agrégés avec celles du vendredi. Et si on ne veut que celles du vendredi, on peut se servir du champ « vrai/faux » créé précédemment pour filtrer les jours non ouvrés.
Mais l’énorme intérêt de ce nouveau champ est qu’il permet très simplement d’effectuer des soustractions entre deux dates en jours ouvrés :
[17/10/2019] - [10/10/2019] = [2] - [-3] = 5 jours ouvrés
Même après rafraichissement des données le 16/10/2019 :
| Jour | Date | Jour ouvré | Diff. jours ouvrés |
|---|---|---|---|
| … | |||
| jeudi | 10/10/2019 | 1 | -4 |
| vendredi | 11/10/2019 | 1 | -3 |
| samedi | 12/10/2019 | 0 | -3 |
| dimanche | 13/10/2019 | 0 | -3 |
| lundi | 14/10/2019 | 1 | -2 |
| mardi | 15/10/2019 | 1 | -1 |
| mercredi | 16/10/2019 | 1 | 0 |
| jeudi | 17/10/2019 | 1 | 1 |
| vendredi | 18/10/2019 | 1 | 2 |
| samedi | 19/10/2019 | 0 | 2 |
| dimanche | 20/10/2019 | 0 | 2 |
| … |
[17/10/2019] - [10/10/2019] = [1] - [-4] = 5 jours ouvrés
Mise en pratique
Les requêtes suivantes permettent de construire une dimension temps comme décrite ci-dessus, pour une base de données Microsoft SQL Server (2016 ou supérieur à cause de l’utilisation de la fonction FORMAT)
Pour commencer, créons la table de la dimension temps, à l’aide du script SQL Suivant :
CREATE TABLE [dbo].[D_CALENDAR](
[CA_ID] [int] NOT NULL,
[CA_MONTH_ID] [int] NOT NULL,
[CA_QUARTER_ID] [int] NOT NULL,
[CA_YEAR] [int] NOT NULL,
[CA_WEEKDAY_ID] [int] NOT NULL,
[CA_WEEK_ID] [int] NOT NULL,
[CA_WEEKYEAR] [int] NOT NULL,
[CA_DAY] [char](2) NOT NULL,
[CA_MONTH] [char](2) NOT NULL,
[CA_QUARTER] [char](1) NOT NULL,
[CA_WEEKDAY] [char](1) NOT NULL,
[CA_WEEK] [char](2) NOT NULL,
[CA_DATE] [date] NOT NULL,
[CA_DATE_SHORT_FR] [varchar](10) NOT NULL,
[CA_DATE_LONG_FR] [varchar](64) NOT NULL,
[CA_DAYNAME_FR] [varchar](32) NOT NULL,
[CA_MONTHNAME_FR] [varchar](32) NOT NULL,
[CA_DATE_SHORT_EN] [varchar](10) NOT NULL,
[CA_DATE_LONG_EN] [varchar](64) NOT NULL,
[CA_DAYNAME_EN] [varchar](32) NOT NULL,
[CA_MONTHNAME_EN] [varchar](32) NOT NULL,
[CA_WORKING_DAY_FLG] [int] NOT NULL,
[CA_DIFF_DAY] [int] NOT NULL,
[CA_DIFF_MONTH] [int] NOT NULL,
[CA_DIFF_QUARTER] [int] NOT NULL,
[CA_DIFF_YEAR] [int] NOT NULL,
[CA_DIFF_WEEK] [int] NOT NULL,
[CA_DIFF_WEEKYEAR] [int] NOT NULL,
[CA_DIFF_WORKING_DAY] [int] NOT NULL
CONSTRAINT [PK_D_CALENDAR] PRIMARY KEY ([CA_ID])
)
Ensuite, ajoutons pour respecter les standards du datawarehousing, une ligne dite « orpheline » utilisable en tant que clé étrangère dans les tables de faits correspondant aux dates non renseignées :
INSERT INTO [dbo].[D_CALENDAR] ([CA_ID] ,[CA_MONTH_ID] ,[CA_QUARTER_ID] ,[CA_YEAR] ,[CA_WEEKDAY_ID] ,[CA_WEEK_ID] ,[CA_WEEKYEAR] ,[CA_DAY] ,[CA_MONTH] ,[CA_QUARTER] ,[CA_WEEKDAY] ,[CA_WEEK] ,[CA_DATE] ,[CA_DATE_SHORT_FR] ,[CA_DATE_LONG_FR] ,[CA_DAYNAME_FR] ,[CA_MONTHNAME_FR] ,[CA_DATE_SHORT_EN] ,[CA_DATE_LONG_EN] ,[CA_DAYNAME_EN] ,[CA_MONTHNAME_EN] ,[CA_WORKING_DAY_FLG] ,[CA_DIFF_DAY] ,[CA_DIFF_MONTH] ,[CA_DIFF_QUARTER] ,[CA_DIFF_YEAR] ,[CA_DIFF_WEEK] ,[CA_DIFF_WEEKYEAR] ,[CA_DIFF_WORKING_DAY]) VALUES (-1,-1,-1,-1,-1,-1,-1,'-','-','-','-','-','1900-01-01','-','-','-','-','-','-','-','-',0,0,0,0,0,0,0,0)
Ensuite alimentons cette table, à l’aide d’une requête récursive générant tous les jours calendaires entre deux années paramétrées :
DECLARE @startDate DATE, @endDate DATE;
SET DATEFIRST 1; -- Monday as first day of week
SET @startDate = '19700101'; -- First generated date
SET @endDate = '20501231'; -- Last generated date
WITH dates AS (
SELECT @startDate CA_DATE
UNION ALL
SELECT DATEADD(DAY,1,CA_DATE) CA_DATE
FROM dates
WHERE CA_DATE < @endDate
)
INSERT INTO D_CALENDAR
SELECT
YEAR(CA_DATE)*10000 + MONTH(CA_DATE)*100 + DAY(CA_DATE) CA_ID
,YEAR(CA_DATE)*100 + MONTH(CA_DATE) CA_MONTH_ID
,YEAR(CA_DATE)*10 + DATEPART(QUARTER, CA_DATE) CA_QUARTER_ID
,YEAR(CA_DATE) CA_YEAR
,YEAR(DATEADD(DAY, (4 - DATEPART(WEEKDAY, CA_DATE)), CA_DATE))*1000 + DATEPART(ISO_WEEK,CA_DATE)*10 + DATEPART(WEEKDAY,CA_DATE) CA_WEEKDAY_ID
,YEAR(DATEADD(DAY, (4 - DATEPART(WEEKDAY, CA_DATE)), CA_DATE))*100 + DATEPART(ISO_WEEK,CA_DATE) CA_WEEK_ID
,YEAR(DATEADD(DAY, (4 - DATEPART(WEEKDAY, CA_DATE)), CA_DATE)) CA_WEEKYEAR
,RIGHT(100 + DAY(CA_DATE),2) CA_DAY
,RIGHT(100 + MONTH(CA_DATE),2) CA_MONTH
,DATEPART(QUARTER, CA_DATE) CA_QUARTER
,DATEPART(WEEKDAY, CA_DATE) CA_WEEKDAY
,RIGHT(100 + DATEPART(ISO_WEEK,CA_DATE),2) CA_WEEK
,CA_DATE
,FORMAT(CA_DATE,'d','fr-fr') CA_DATE_SHORT_FR
,FORMAT(CA_DATE,'D','fr-fr') CA_DATE_LONG_FR
,FORMAT(CA_DATE,'dddd','fr-fr') CA_DAYNAME_FR
,FORMAT(CA_DATE,'MMMM','fr-fr') CA_MONTHNAME_FR
,FORMAT(CA_DATE,'d','en-US') CA_DATE_SHORT_EN
,FORMAT(CA_DATE,'D','en-US') CA_DATE_LONG_EN
,FORMAT(CA_DATE,'dddd','en-US') CA_DAYNAME_EN
,FORMAT(CA_DATE,'MMMM','en-US') CA_MONTHNAME_EN
,0 CA_WORKING_DAY_FLG
,0 CA_DIFF_DAY
,0 CA_DIFF_MONTH
,0 CA_DIFF_QUARTER
,0 CA_DIFF_YEAR
,0 CA_DIFF_WEEK
,0 CA_DIFF_WEEKYEAR
,0 CA_DIFF_WORKING_DAY
FROM dates
OPTION (MAXRECURSION 32767)
Puis alimentons le calendrier des jours ouvrés (pour l’exemple, selon la règle lundi-vendredi = jour ouvré, samedi-dimanche=jour férié)
UPDATE D_CALENDAR SET CA_WORKING_DAY_FLG = 1 WHERE CA_WEEKDAY IN (1,2,3,4,5)
Enfin alimentons les champs différentiels avec la requête suivante :
DECLARE @today DATE;
SET DATEFIRST 1; -- Monday as first day of week
SET @today = GETDATE(); -- Define date reference for differential calculations
WITH WORKING_DAY_COUNTERS AS (
SELECT
CA_ID
,SUM(CA_WORKING_DAY_FLG) OVER (ORDER BY CA_ID) WORKING_DAY_COUNT
,SUM(CASE WHEN DATEDIFF(DAY,@today,CA_DATE) <= 0 THEN CA_WORKING_DAY_FLG ELSE 0 END) OVER () TODAY_WORKING_DAY_COUNT
FROM D_CALENDAR
WHERE CA_ID <> -1
)
UPDATE D_CALENDAR SET
CA_DIFF_DAY = DATEDIFF(DAY,@today,CA_DATE)
,CA_DIFF_MONTH = DATEDIFF(MONTH,@today,CA_DATE)
,CA_DIFF_QUARTER = DATEDIFF(QUARTER,@today,CA_DATE)
,CA_DIFF_YEAR = DATEDIFF(YEAR,@today,CA_DATE)
,CA_DIFF_WEEK = DATEDIFF(WEEK,@today,DATEADD(DAY, (4 - DATEPART(WEEKDAY, CA_DATE)), CA_DATE))
,CA_DIFF_WEEKYEAR = CA_WEEKYEAR-YEAR(@today)
,CA_DIFF_WORKING_DAY = WORKING_DAY_COUNTERS.WORKING_DAY_COUNT - WORKING_DAY_COUNTERS.TODAY_WORKING_DAY_COUNT
FROM D_CALENDAR
INNER JOIN WORKING_DAY_COUNTERS
ON D_CALENDAR.CA_ID = WORKING_DAY_COUNTERS.CA_ID
WHERE D_CALENDAR.CA_ID <> -1
A noter que cette dernière requête doit être rejouée à chaque rafraichissement du datawarehouse afin recalculer les valeurs différentielles par rapport à la date du jour.
Voici un aperçu de la table une fois alimentée :