Les solutions d’intégration de données traditionnelles, conçues pour des formats de données simples, comme des tables et des fichiers plats, sont confrontées à des taux de productivité et de performance pauvres lorsqu’il s’agit de traiter des formats de données hiérarchiques telles que XML, JSON, les IDOCs SAP ou bien encore les Web Services.
L’objectif de cet article est de présenter comment gérer efficacement les fichiers hiérarchiques de type JSON et XML grâce à l’ELT Stambia, qui a été conçu dans l’optique de fournir le même niveau de simplicité et de performance quelle que soit la forme des données à traiter.
Sommaire
- Sommaire
- Les fichiers JSON (JavaScript Object Notation)
- Lecture d’un fichier JSON
- Représentation des données JSON par des Métadonnées
- Paramétrage du répertoire d’extraction et du nom du fichier
- Lecture de nœuds avec des noms différent
- Charger les données JSON
- Créer un fichier JSON
- Les fichiers XML (eXtensible Markup Language)
- Lecture d’un fichier XML
- Représentation des données XML par des Métadonnées
- Lecture du fichier
- Ecriture d’un fichier XML
- Conclusion
Les fichiers JSON (JavaScript Object Notation)
Le JSON est un format de données textuelles dérivé de la notation des objets du langage JavaScript. Il permet de représenter de l’information structurée et est plus léger qu’un fichier XML avec une même quantité de données. C’est la raison pour laquelle JSON prend largement la place du XML dans les échanges de données et notamment dans la communication avec des web services.
On retrouve dans la structure des fichiers .json ces quelques signes de ponctuations :
- les accolades qui définissent un objet : {…}
- Les guillemets (double-quotes) et les double-points qui définissent un couple clé/valeur (on parle de membre) : « langage »: « Java »
- Les crochets qui définissent un tableau : […]
- Les virgules qui permettent de séparer les membres d’un tableau ou, comme ici, d’un objet : {« id »:1, « langage »: « json », « auteur »: « Douglas »}
Grâce à leurs avantages, de plus en plus de données sont stockées dans des structures fichiers plats ou fichiers hiérarchiques (Json, XML,…), dont certaines très spécifiques au domaine du Big Data. Cependant, la gestion de données hiérarchiques s’avère parfois coûteuse en terme de temps de développement et parfois peu efficace. L’ELT Stambia permet de traiter, de façon très simple, les fichiers JSON, que ce soit en lecture ou en écriture.
Lecture d’un fichier JSON
Le Designer Stambia permet de lire directement les données hiérarchiques de type JSON. En effet, De nombreux assistants permettent d’aider l’utilisateur dans la récupération des métadonnées. Ils sont adaptés à chaque technologie, prenant en compte chacune des spécificités. Une fois que la description du fichier a été faite, il est possible d’effectuer de simples commandes SQL pour lire le fichier comme s’il était composé de plusieurs tables.
Représentation des données JSON par des Métadonnées
- Création d’une métadonnée de type JSON :
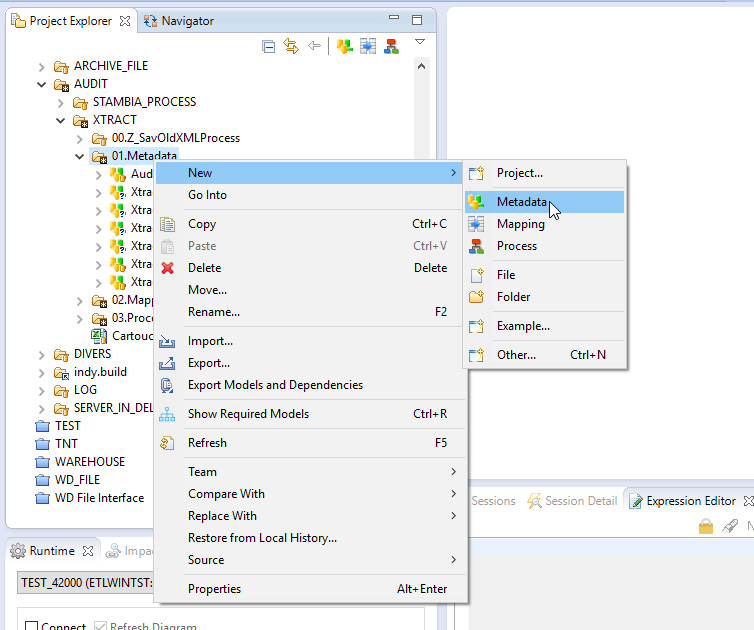
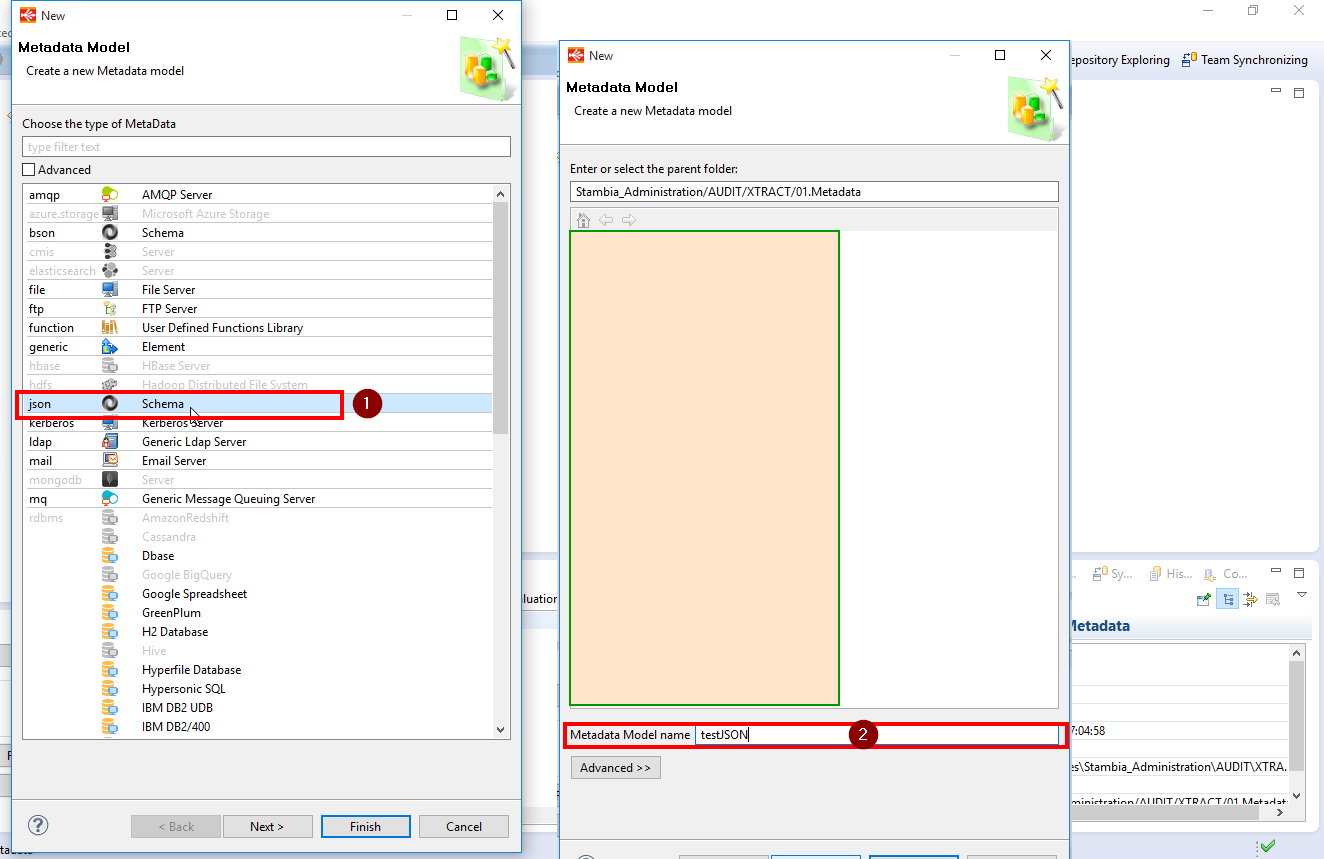
Lors de la création de la métadonnée, il est possible de fournir le schéma de données (structure des fichiers JSON). Cependant, cette structure peut-être définie plus tard via le menu contextuel
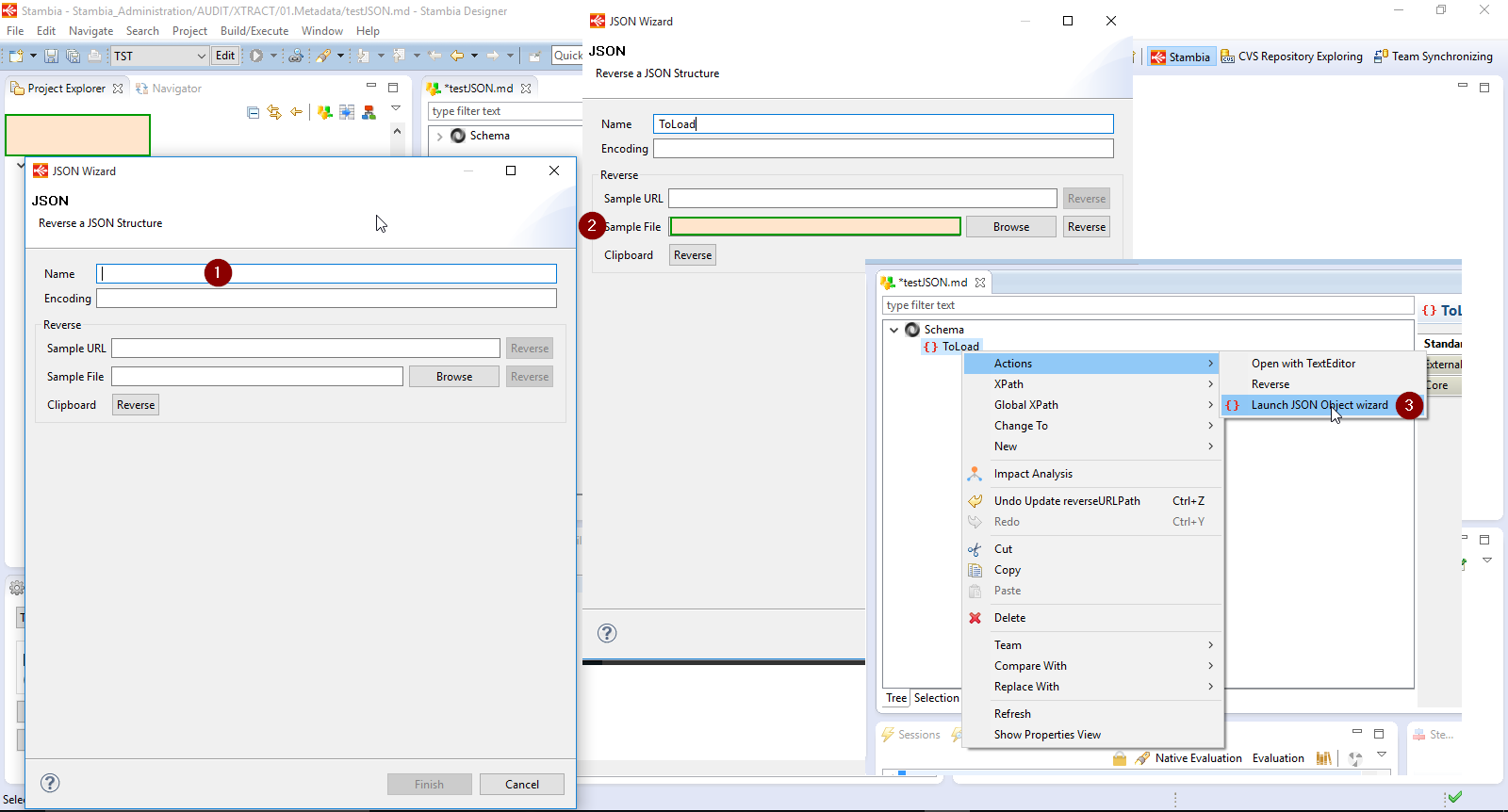
- Reverse de la métadonnée :
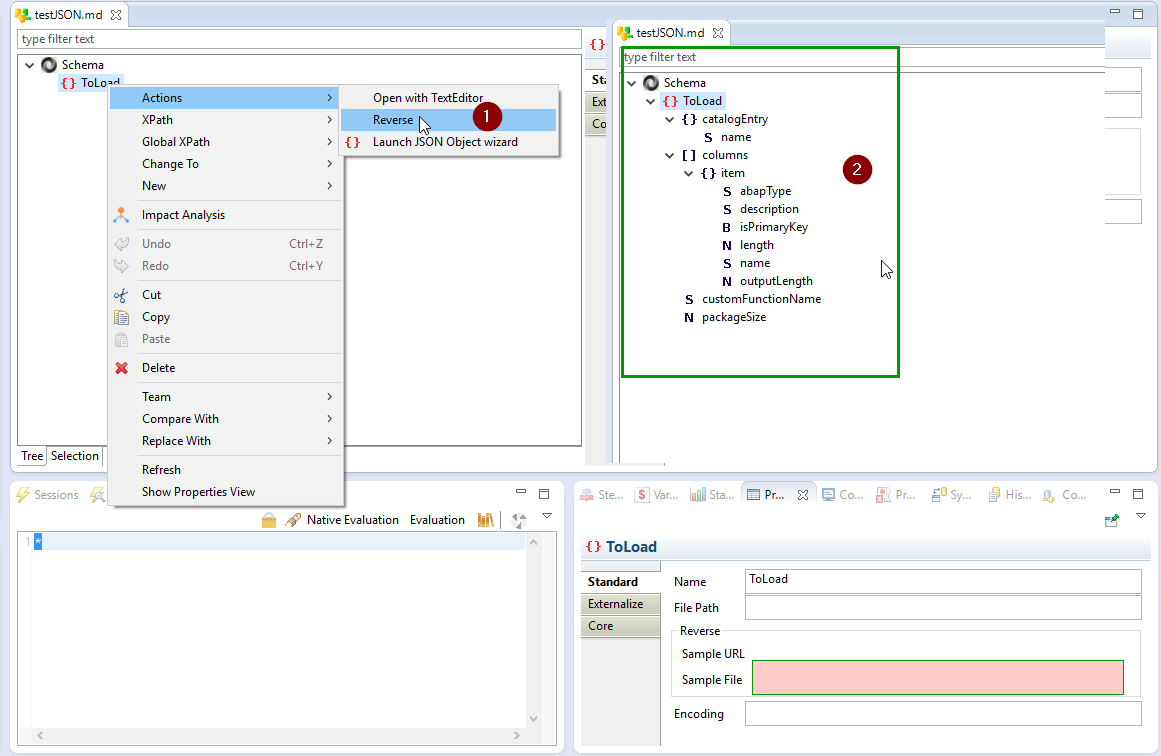
Pour récupérer la structure choisie, il suffit de faire un reverse de la métadonnée créée
Paramétrage du répertoire d’extraction et du nom du fichier
La localisation des fichiers peut être fournie sous forme de variable (autre métadonnée). Cela permet par exemple, de charger des fichiers provenant de différents répertoires, dépendant par exemple de l’environnement d’exécution.
Il est donc aussi possible de charger des fichiers ayant la même structure (définie lors de la création de la métadonnée) mais dont les noms diffèrent (Exemple : chargement de fichiers Logs dont les noms sont rendus unique grâce à un Timestamp.
L’ajout des liens se fait par un glissement de la métadonnée indiquant le nom du répertoire/fichier dans la métadonnée JSON.
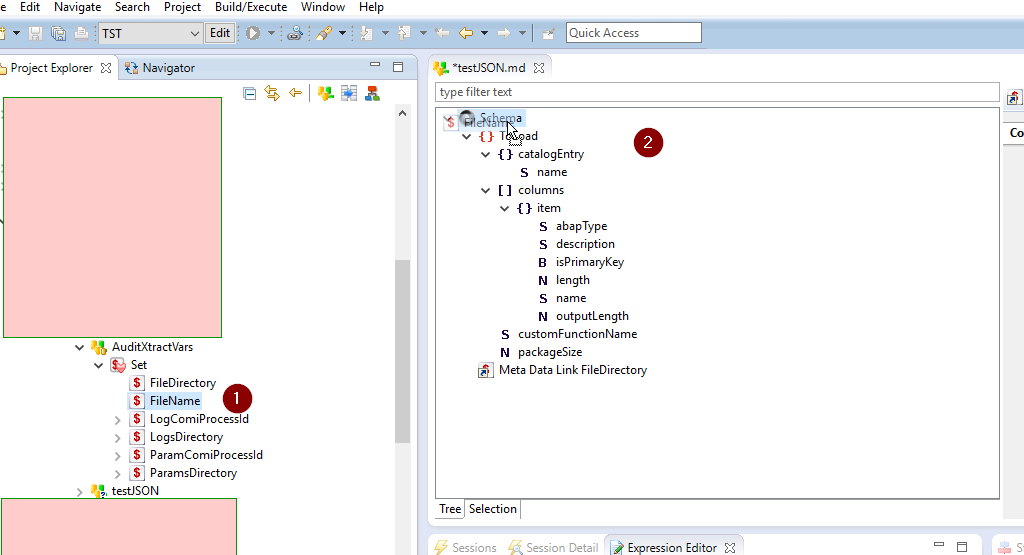
Il faudra donc indiquer à la métadonnée JSON l’emplacement dynamique du fichier à charger :
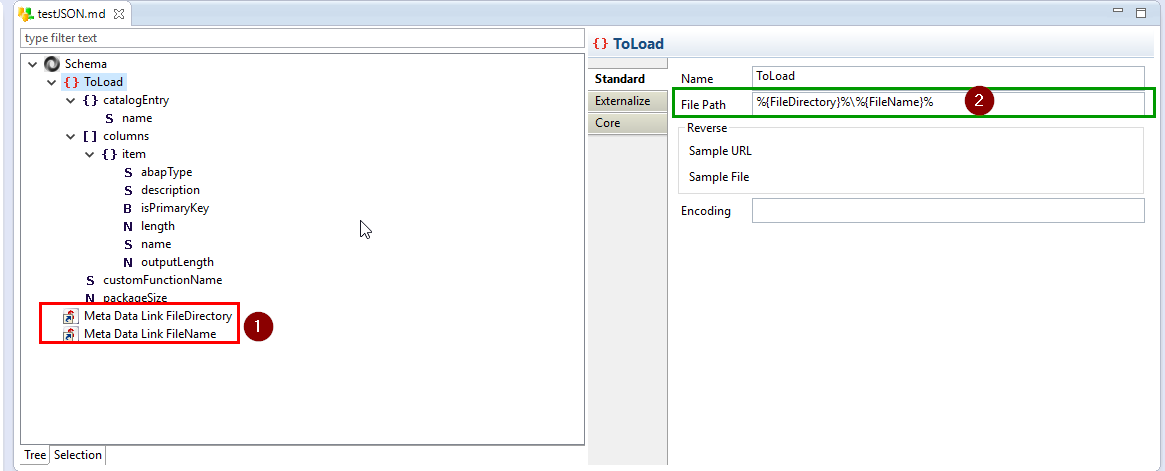
En outre, il est aussi possible de définir la configuration directement dans la métadonnée JSON
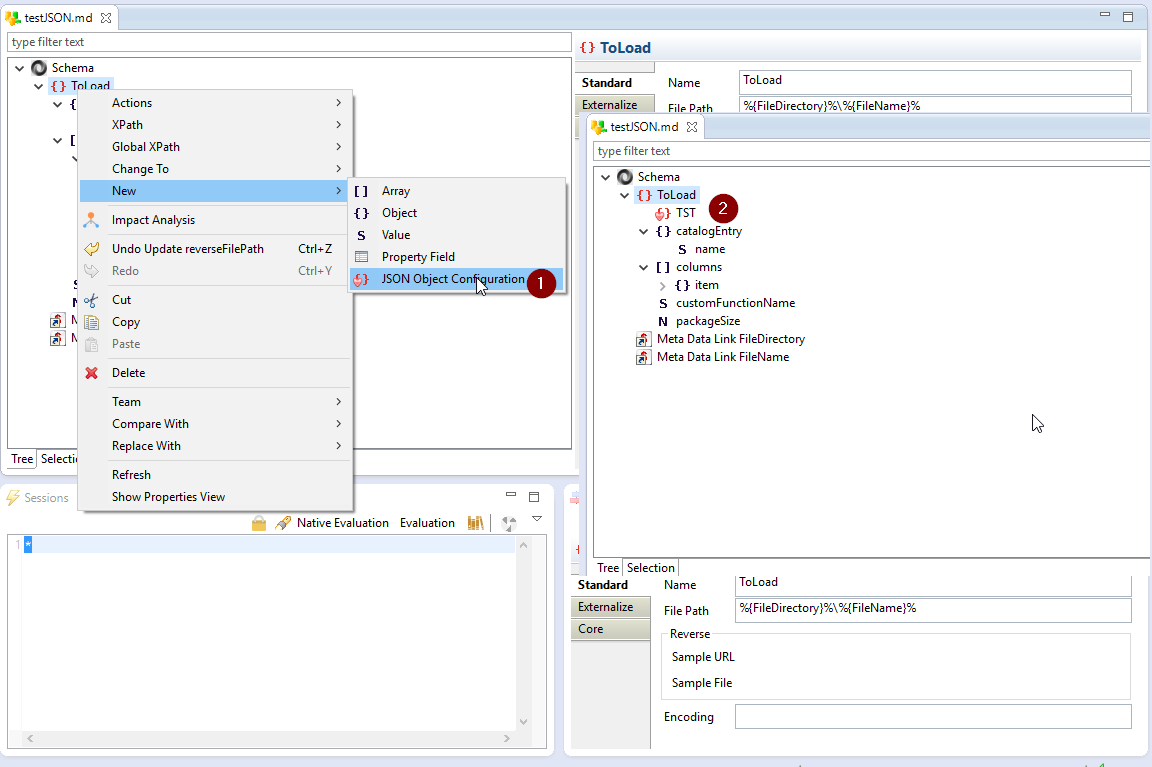
Il est possible, lors de la lecture du fichier JSON via la métadonnée, de récupérer les propriétés du fichier chargé telles que les chemins d’accès au fichier (canonique et absolu), le nom du fichier, les noms des nœuds, …
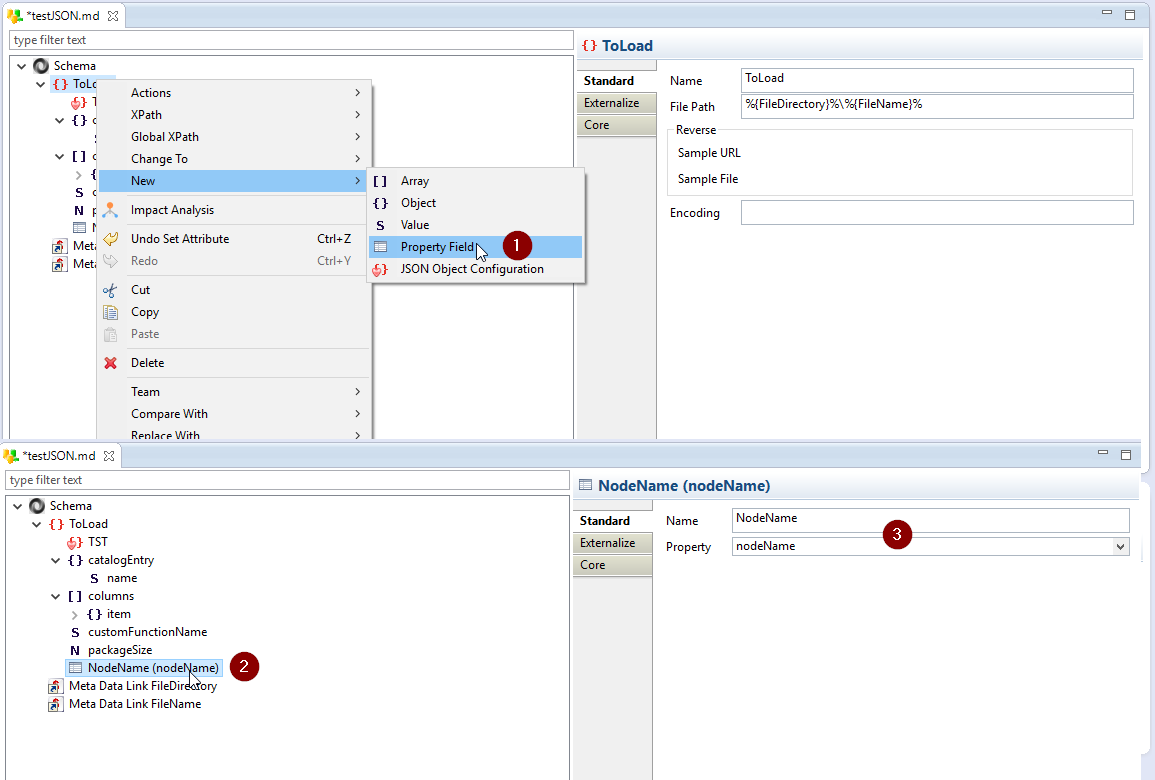
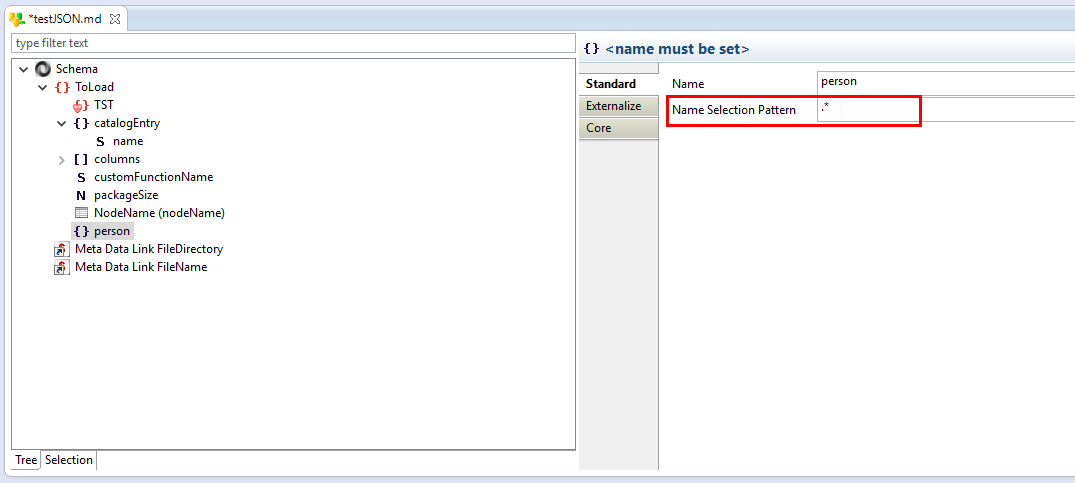
Lecture de nœuds avec des noms différent
Parfois, le nom d’un nœud JSON peut contenir lui-même des informations sur les données. Dans ce cas, le nom du nœud variera sur chaque fichier, sur chaque occurrence ou exécution. Il est possible de lire facilement ce type de nœuds en spécifiant un modèle de nom (une expression régulière) dans les métadonnées. En lecture, si le nom correspond à l’expression régulière spécifiée, le Runtime chargera le nœud.
Charger les données JSON
La gestion de données hiérarchiques ne présente aucune différence comparée à l’usage des autres types de données.
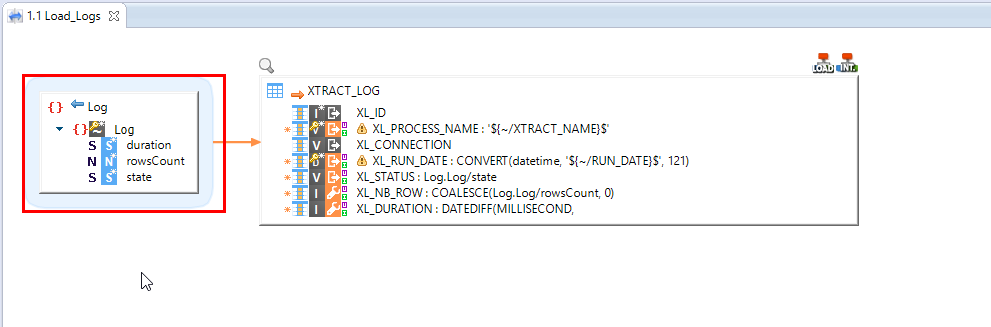
Un simple « glisser/déposer » sur les tables cibles permet de réaliser le mapping. Par défaut, les données sont chargées en parallèle, Stambia optimisant ainsi la lecture et l’écriture des données. Lors de la manipulation d’un fichier hiérarchique en source dans un mapping, Stambia met en commun la lecture du fichier (ou de la source hiérarchique) pour l’ensemble des besoins du mapping. La lecture ne se fait pas en mémoire, mais en mode « stream » pour optimiser la gestion des ressources.
Créer un fichier JSON
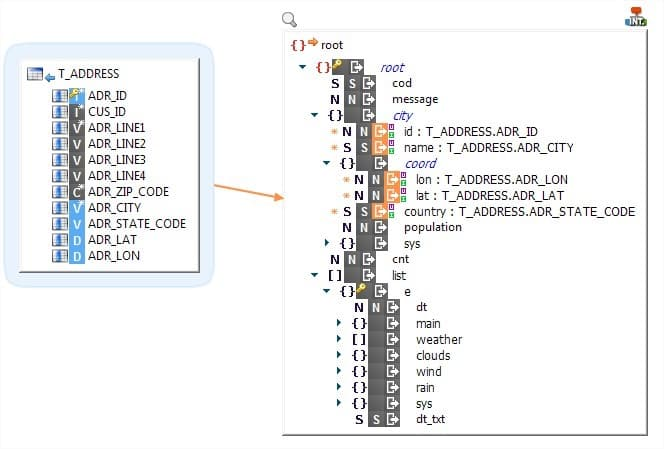
Stambia peut intégrer les données dans un fichier ou structure hiérarchique en un seul mapping et ce quelle que soit la complexité de la structure adressée. Ainsi, tout en restant lisible, un seul mapping permettra de produire un fichier hiérarchique unique, pouvant contenir des hiérarchies très profondes, ou bien contenir de multiples occurrences de mêmes éléments, ou bien encore des hiérarchies juxtaposées.
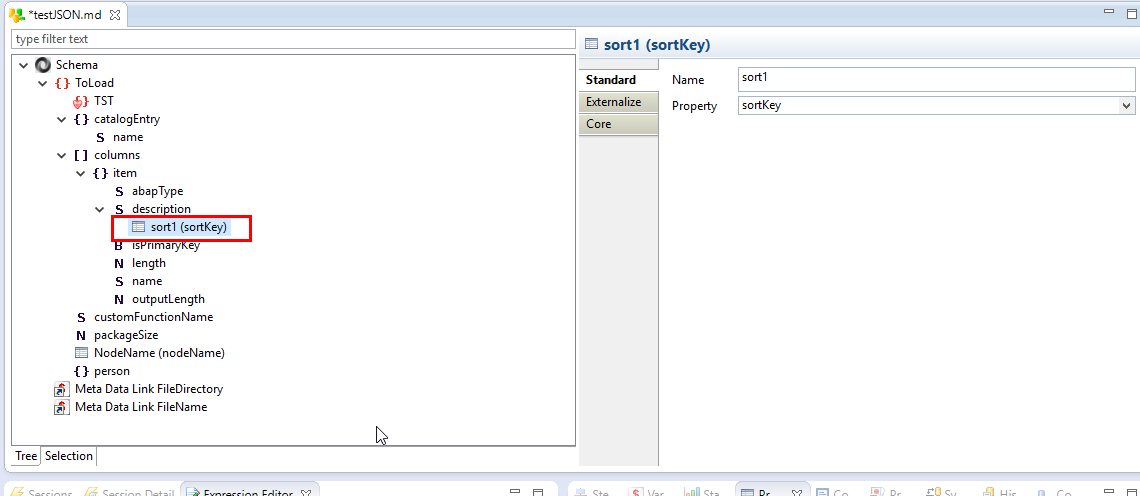
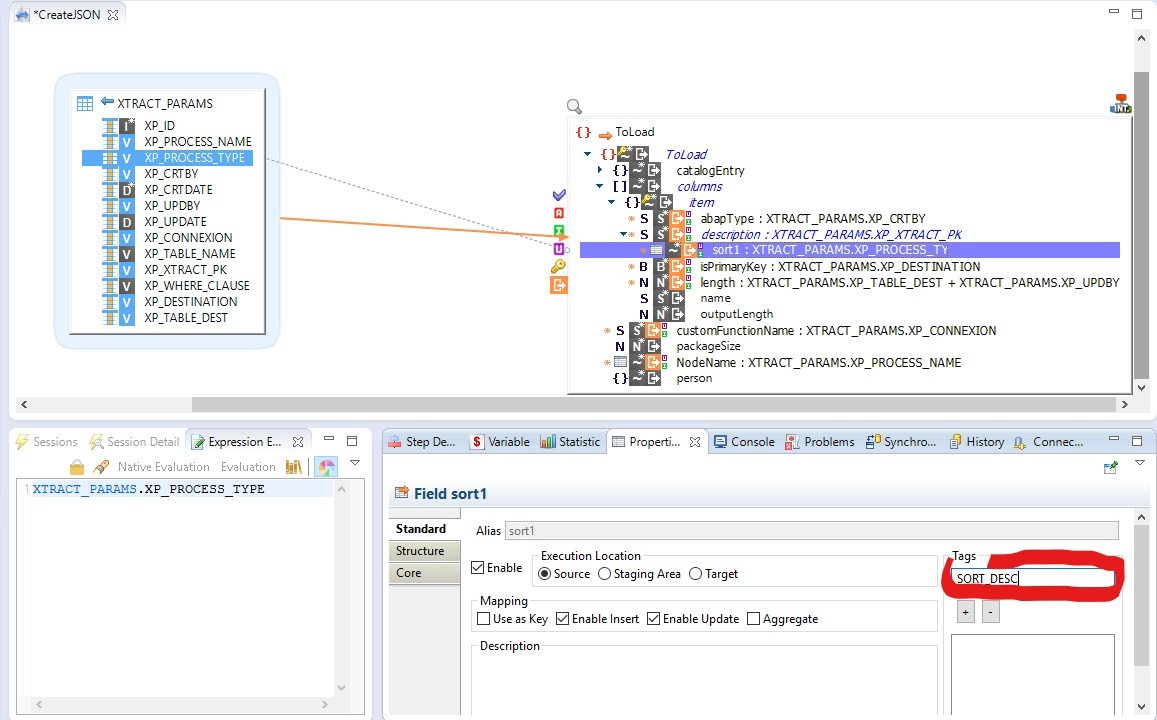
Lors de l’écriture d’un fichier JSON, les données peuvent être triées à l’aide de clés de tri. La première étape consiste à ouvrir les métadonnées JSON pour ajouter les champs qui seront ensuite utilisés dans les mappings pour trier les données. Pour cela, il faut simplement ajouter autant de champs de propriété ‘sortKey’ que nécessaire sous le nœud à trier.
Par défaut, les clés spécifiées trient les données dans l’ordre croissant. Ce comportement peut être modifié en ajoutant l’une des balises suivantes sur la clé de tri : SORT_ASC, SORT_DESC
Les fichiers XML (eXtensible Markup Language)
XML est un format de données standard, il est utilisé pour stocker et transmettre des données hiérarchiques afin de les partager entre applications ou avec des réseaux d’entreprise. Comme le langage HTML, XML utilise les balises pour structurer les données. Le langage XML est constitué généralement de deux composants de base : les éléments et les attributs. Les éléments sont utilisés pour marquer les sections d’un document XML, un élément XML se présente comme suit :
<Element>Contenu</Element>
Le contenu de l’élément est placé entre les deux balises, les éléments d’un fichier XML peuvent être imbriqués.
Les attributs sont utilisés pour ajouter des informations descriptives à un élément, ils sont inclus dans la première balise d’un élément, la valeur de l’attribut doit être placée entre guillemets :
<Element Attribut="Valeur">Contenu</Element>
Stambia permet de manipuler des fichiers XML de manière simple et efficace. Grace au reverse engineering de Stambia, un fichier XML peut être modélisé en métadonnées en utilisant son schéma XSD, les métadonnées peuvent également être générées à partir d’un fichier d’exemple si le schéma XSD n’est pas disponible.
Dans cet article, nous allons appliquer les fonctionnalités présentées par Stambia sur un fichier XML contenant les données des commandes :
<?xml version="1.0" encoding="windows-1252"?>
<Commande N_commande="542892" Ref_client="F/759626">
<Code_produit>6903</Code_produit>
<Quantite>12.0</Quantite>
<Prix_HT_produit>9.55</Prix_HT_produit>
<Date_commande>15/07/2009</Date_commande>
<Livraison>
<Date_expedition_demande>15/07/2009</Date_expedition_demande>
<Livraison_partiel>O</Livraison_partiel>
<Code_transport>HCO</Code_transport>
<Code_Livraison>PR</Code_Livraison>
</Livraison>
<Destinataire>
<Adresse>NOVOPHTALMIQUE SAS ZONE INDUSTRIELLE LA MOISERIE PORTE B</Adresse>
<Code_postal>2404</Code_postal>
<Ville>CHATEAU THIERRY CEDEX</Ville>
<Pays>1</Pays>
</Destinataire>
</Commande>
Lecture d’un fichier XML
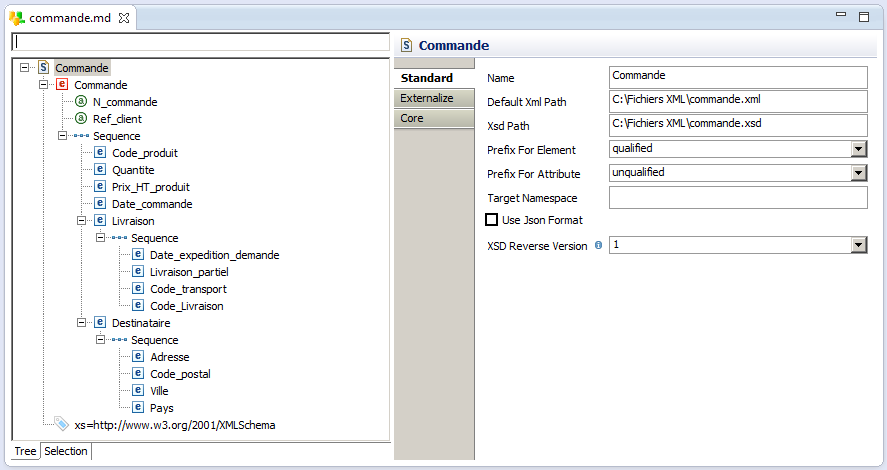
Représentation des données XML par des Métadonnées
Le fichier commande.xml sera déclaré comme une métadonnée dans Stambia, l’opération du reverse engineering permettra par la suite de récupérer la structure du fichier. La métadonnée du fichier commandes.xml peut être générée soit à partir du fichier XSD correspondant ou à partir du fichier XML d’exemple. Pour représenter le fichier commande.xml, nous avons créé une métadonnée de type « Schéma XML ». Après l’opération du reverse engineering, Stambia génère une métadonnée de type ‘Schéma XML’ :
Lecture du fichier
Pour lire les données du fichier XML, nous avons créé le mapping suivant :
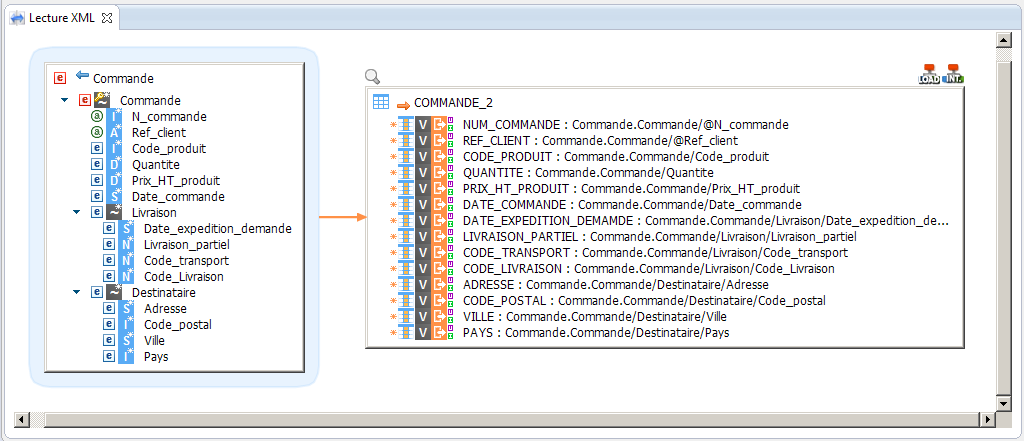
Le mapping de Stambia permet une lecture des structures XML en toute simplicité quelle que soit la complexité de ces structures. Cela est effectué grâce à des liaisons entre les composants XML (attributs, éléments) et les colonnes de la table de base de données. Il est également possible d’intégrer les données d’un seul fichier XML dans des tables de base de données différentes, tout en utilisant un seul mapping.
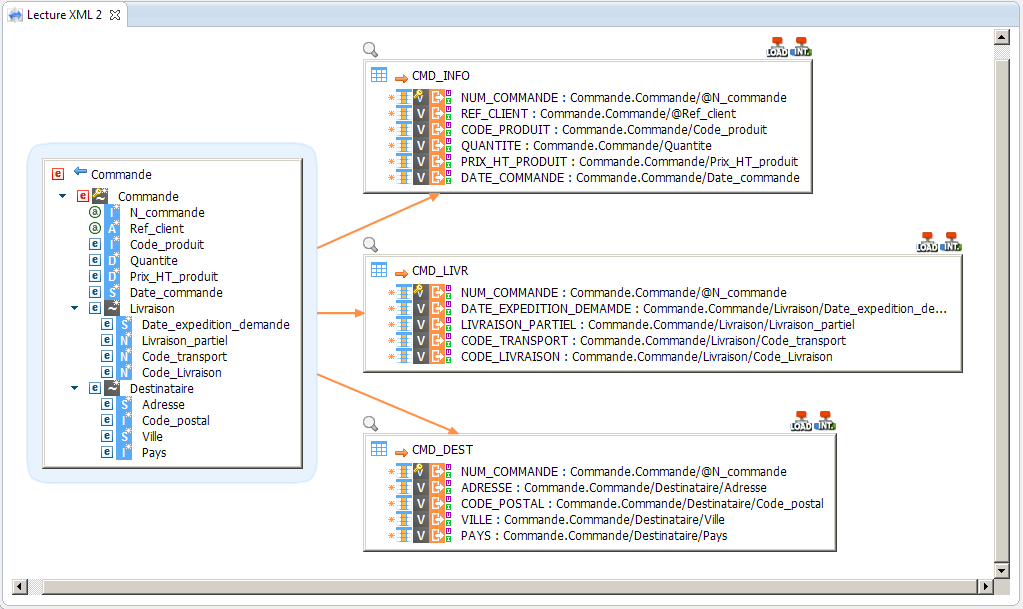
Stambia permet également de lire plusieurs fichiers XML en utilisant un seul mapping, ces fichiers doivent avoir la même structure. Cela peut être utilisé pour lire les fichiers générés par un logiciel ou pour lire les fichiers reçus à partir d’un serveur FTP. Pour traiter plusieurs fichiers XML dans un seul mapping, il suffit d’ajouter un masque dans le chemin du fichier XML pour déclarer une métadonnée générale pour tous les fichiers d’un dossier. Si par exemple nos fichiers de commande sont appelés de la façon suivante : commande_[NUM_COMMANDE].xml, le chemin de la métadonnée sera : C:\Fichiers XML\commande*.xml.
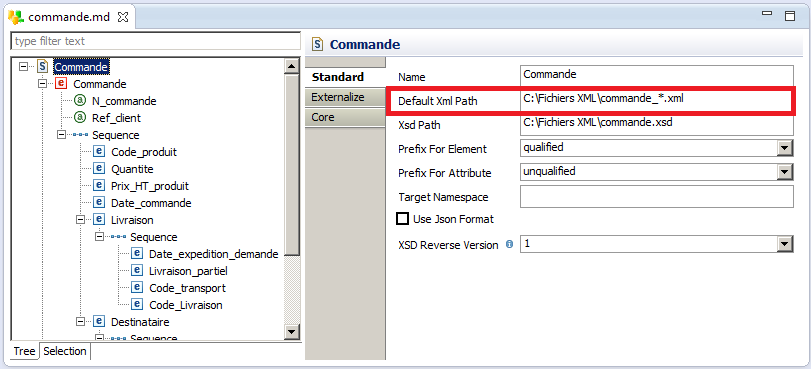
Une fois la métadonnée modifiée pour prendre en compte plusieurs fichiers à la fois, on va pouvoir utiliser les mêmes mappings présentés au-dessus pour intégrer les fichiers dans la table de base de données.
Ecriture d’un fichier XML
Avec l’outil Stambia, il est possible de générer des fichiers XML à partir des données stockées dans des tables de base de données. Une fois la métadonnée XML cible définie, cela peut être fait à l’aide d’un simple mapping :
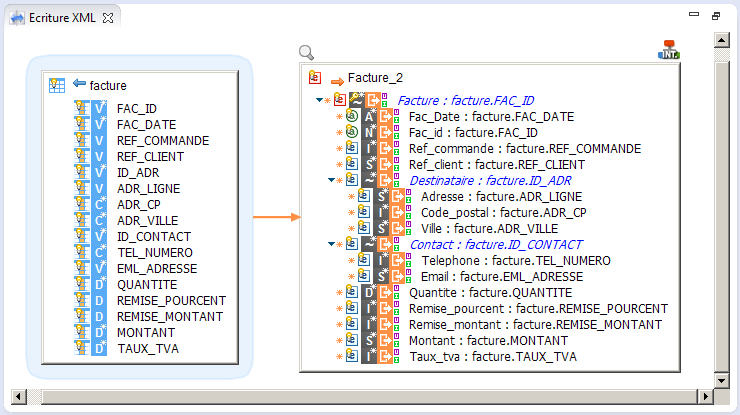
Le nom et le chemin du fichier de sortie doivent être spécifiés dans les paramètres de l’étape intégration de l’élément Facture_2, le champ Out File Name permet de définir un nom fixe pour le fichier de sortie :
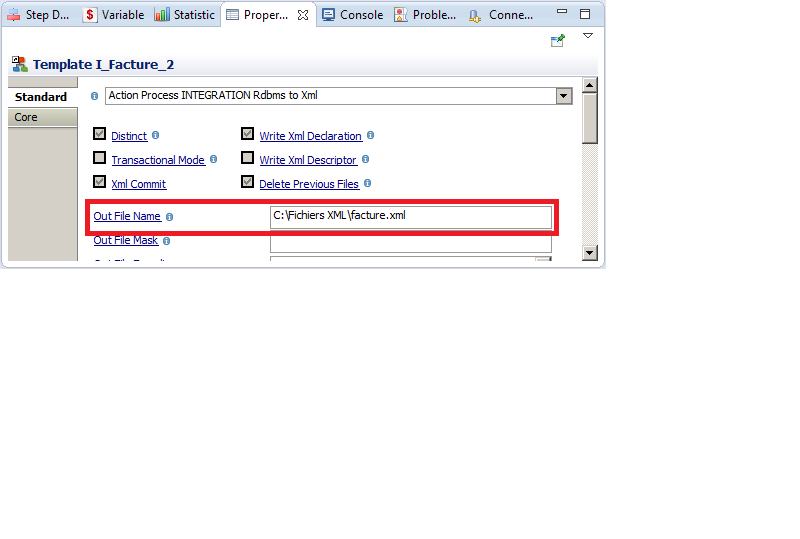
Stambia permet également de générer un fichier XML pour chaque enregistrement de la table source, dans notre cas, nous allons pouvoir générer plusieurs fichiers XML, chaque fichier correspond à une facture (ligne de table facture) et sera créé avec un nom dynamique.
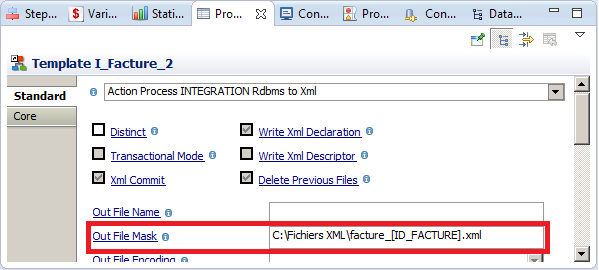
Pour cela, nous allons utiliser le Mapping d’écriture XML précédent, tout en renseignant le champ Out File Mask, sa différence avec le champ Out File Name est qu’il permet de générer un nom variable qui sera différent pour chaque fichier créé. Le nom du fichier cible pourra être composé d’une chaine de caractère suivie d’une information spécifique à la facture, par exemple : facture_[Identifiant de la facture].xml
Pour pouvoir utiliser le champ Fac_id comme paramètre dans le nom dynamique, il faut ajouter un Tag sur ce champ dans le Mapping :
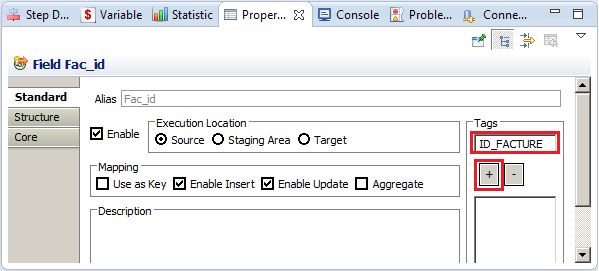
Une fois le Tag ajouté, nous allons pouvoir l’utiliser dans le « mask » du fichier de sortie :
Conclusion
La gestion des fichiers hiérarchiques avec Stambia se fait d’une manière simple et efficace, ce qui permet de gagner en productivité et d’accélérer le traitement des fichiers hiérarchiques. De plus, la simplicité des solutions proposées par Stambia permet de manipuler des fichiers hiérarchiques avec des formats spécifiques sans avoir des connaissances avancées dans une telle technologie et indépendamment de leur complexité.