Lors de la conception d’un Entrepôt de données (ou datawarehouse), la question de la performance est au cœur de celle-ci. En effet au moment du reporting, il est fondamental que les temps de réponse soient constants pour une volumétrie croissante. C’est pour cela qu’il est important de construire les tables de dimensions et de faits, de manière à ce que l’on fasse uniquement des jointures fermées (INNER JOINS).
Cependant il peut arriver que lors de l’alimentation d’une table de faits, certaines lignes n’aient pas de correspondance avec une ou plusieurs tables de dimensions. Comment gérer ces cas, pour quand même intégrer ces lignes de manière cohérente et conserver toutes les données dans notre datawarehouse ? C’est là qu’intervient l’utilisation du fameux IDENTITY_INSERT.
1. Structure des tables
Pour illustrer son utilisation, nous allons nous servir d’un exemple simple, basique : une table de faits appelé FACT et deux tables de dimensions appelées : DIM_TIME et DIM_GEO.
La table DIM_TIME contient les années et les mois, et la table DIM_GEO contient les pays et les villes. Chaque table possède un identifiant unique auto-incrémenté, TIME_ID et GEO_ID :
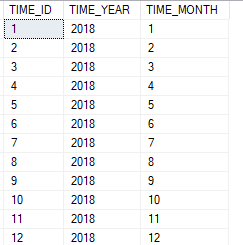
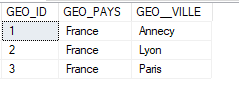
La table de faits est composée d’une clé unique, de deux mesures (Chiffre d’affaire et budget), ainsi que de deux clés étrangères faisant référence aux deux tables de dimensions. Pour l’instant elle est vide :
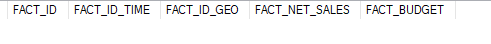
2. Alimentation de la table de faits
Utilisons ce script d’insertion de données :
INSERT INTO [dbo].[FACT]([FACT_ID_TIME],[FACT_ID_GEO],[FACT_NET_SALES],[FACT_BUDGET]) VALUES (1,1,1000,900) ,(2,1,2000,2200) ,(3,1,1500,3000) ,(4,1,3000,2555) ,(5,1,4568,5000) ,(6,1,8000,7500) ,(7,1,3000,6000) ,(8,1,3567,1000) ,(9,1,6740,6500) ,(10,1,6382,3800) ,(11,1,8383,8000) ,(12,1,7400,7400) ,(1,2,1150,1035) ,(2,2,2300,2530) ,(3,2,1725,3450) ,(4,2,3450,2938.25) ,(5,2,5253.2,5750) ,(6,2,9200,8625) ,(7,2,3450,6900) ,(8,2,4102.05,1150) ,(9,2,7751,7475) ,(10,2,7339.3,4370) ,(11,2,9640.45,9200) ,(12,2,8510,8510) ,(1,3,1322.5,1190.25) ,(2,3,2645,2909.5) ,(3,3,1983.75,3967.5) ,(4,3,3967.5,3378.99) ,(5,3,6041.18,6612.5) ,(6,3,10580,9918.75) ,(7,3,3967.5,7935) ,(8,3,4717.36,1322.5) ,(9,3,8913.65,8596.25) ,(10,3,8440.2,5025.5) ,(11,3,11086.52,10580) ,(12,3,9786.5,9786.5)
Voici le résultat dans la table de FACT :
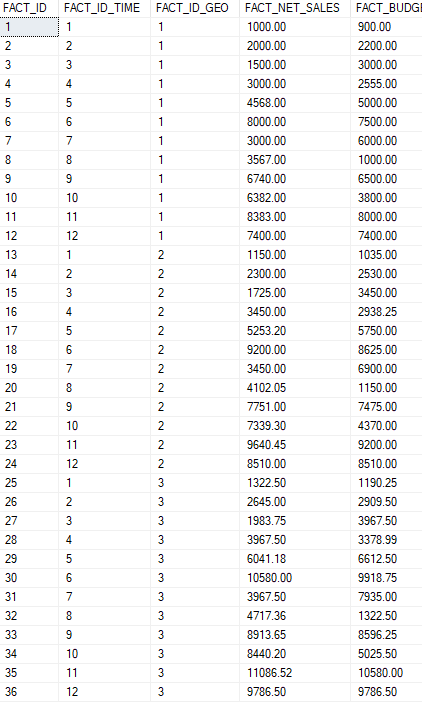
On remarque que dans ce script, chaque ligne à insérer possède bien un identifiant connu vers les tables de dimensions. En faisant une requête d’analyse par année et par ville, nous obtenons le résultat suivant :
SELECT T.TIME_YEAR 'Année'
,G.GEO_VILLE 'Ville'
,SUM(F.FACT_NET_SALES) 'CA'
,SUM(F.FACT_BUDGET) 'Budget'
FROM FACT F
INNER JOIN DIM_TIME T
ON F.FACT_ID_TIME = T.TIME_ID
INNER JOIN DIM_GEO G
ON F.FACT_ID_GEO = G.GEO_ID
GROUP BY T.TIME_YEAR
,G.GEO_VILLE
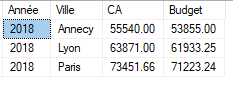
Cependant, que se passe-t-il si sur une des lignes, un des identifiants de dimensions n’est pas connu ? Pour l’exercice nous mettrons dans ce cas la valeur -1.
Imaginons le script suivant :
INSERT INTO [dbo].[FACT] ([FACT_ID_TIME],[FACT_ID_GEO],[FACT_NET_SALES],[FACT_BUDGET]) VALUES (1,-1,2000,1800) ,(2,-1,4000,4400) ,(3,-1,3000,6000) ,(4,-1,6000,5110) ,(5,-1,9136,10000) ,(6,-1,16000,15000) ,(7,-1,6000,12000) ,(8,-1,7134,2000) ,(9,-1,13480,13000) ,(10,-1,12764,7600) ,(11,-1,16766,16000) ,(12,-1,14800,14800)
On remarque que l’identifiant sur la dimension DIM_GEO est renseigné avec -1. Ce qui donne le résultat suivant dans la table de faits :
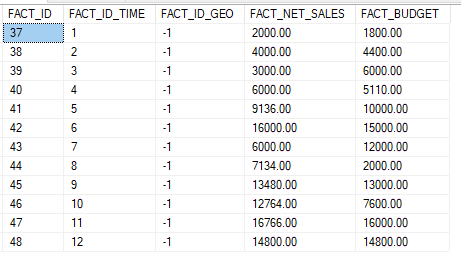
Nous allons alors parler de lignes « orphelines » au regard de la dimension DIM_GEO. Si nous rejouons notre requête d’analyse, le résultat reste le même et les données insérées ci-dessus n’apparaissent pas, car filtrées par les jointures fermées entre la table FACT et les dimensions :
SELECT T.TIME_YEAR 'Année'
,G.GEO_VILLE 'Ville'
,SUM(F.FACT_NET_SALES) 'CA'
,SUM(F.FACT_BUDGET) 'Budget'
FROM FACT F
INNER JOIN DIM_TIME T
ON F.FACT_ID_TIME = T.TIME_ID
INNER JOIN DIM_GEO G
ON F.FACT_ID_GEO = G.GEO_ID
GROUP BY T.TIME_YEAR
,G.GEO_VILLE

Le fait de ne pas voir les données laisserait à penser qu’elles n’ont pas été intégrées dans la table, ce qui n’est pas le cas. La question est donc de savoir comment procéder pour faire apparaitre ces données dans les analyses, pour que le montant global soit ainsi juste, sans sacrifier les jointures fermées qui contribuent aux bonnes performances générales des requêtes d’analyse.
3. Utilisation de l’IDENTITY_INSERT
La première intuition est de se dire que l’on va créer une ligne dans la table DIM_GEO avec dans la colonne GEO_ID la valeur -1. Malheureusement SQL Server ne le permet pas sur une colonne auto-incrémentée :
INSERT INTO [dbo].[DIM_GEO] (GEO_ID,[GEO_PAYS],[GEO_VILLE]) VALUES ( -1,'N/A','N/A')

La requête renvoie une erreur, indiquant que l’option IDENTITY_INSERT n’est pas activée. Nous avons ici une petite indication pour résoudre le problème.
L’activation de cette propriété, va nous permettre d’autoriser l’insertion de valeurs explicites dans la colonne GEO_ID de la table DIM_GEO. Par défaut cette propriété est inactive sur les tables.
La syntaxe est la suivante :
SET IDENTITY_INSERT [[<DATABASE_NAMEE>.]<SCHEMA_NAME>].]<TABLE_NAME> ON|OFF
Pour ce faire nous devons donc activer cette option, et surtout ne pas oublier de la désactiver par la suite :
SET IDENTITY_INSERT DIM_GEO ON INSERT INTO [dbo].[DIM_GEO] (GEO_ID,[GEO_PAYS],[GEO_VILLE]) VALUES ( -1,'N/A','N/A') SET IDENTITY_INSERT DIM_GEO OFF

On voit que notre ligne a bien été insérée dans la table DIM_GEO. Nous avons mis comme valeur ‘N/A’ dans les colonnes pays et ville, pour que lors du reporting les données sortent avec un libellé explicite.
Si nous rejouons notre requête d’analyse, les nouvelles données apparaissent bien :
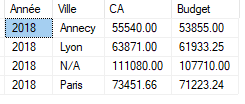
Fonctionnellement, il faut ensuite se poser la question, de quelles valeurs nous attribuons à ces lignes orphelines pour avoir des vraies valeurs dans la table de dimension.
Petit bonus : voici une requête permettant d’intégrer dans une table de dimension une valeur correspondant au lignes de faits orphelines, si et seulement si elle n’existe pas déjà dans la table. Par exemple dans la table DIM_TIME :
SET IDENTITY_INSERT TIME ON;
INSERT INTO DIM_TIME (TIME_ID, TIME_YEAR, TIME_MONTH)
SELECT - 1
, 9999
, 99
WHERE NOT EXISTS (
SELECT 1
FROM DIM_TIME
WHERE TIME_ID = - 1
);
SET IDENTITY_INSERT TIME OFF;