Stambia permet d’importer très facilement des fichiers plats en base et cela va nous servir à facilement comparer le contenu de 2 fichiers et ce sans tenir compte de leur format.
En effet, en décidant d’importer un fichier comme s’il était de type fichier plat délimité, on se soustrait au type réel du fichier à comparer et on ne compare plus que le contenu. Cela fonctionne donc pour de nombreux fichiers tels que XML, XSD, TXT, CSV, IDOC, etc…
Note : Pour chaque élément présenté, le projet est fourni dans l’archive zip disponible ci-dessous et importable dans Stambia.
Mapping
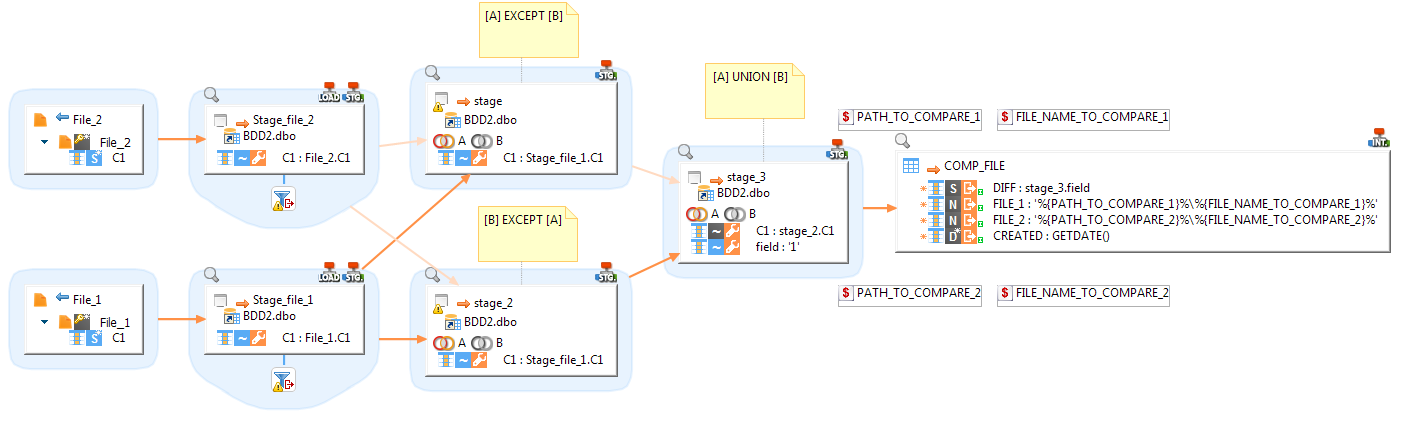
Le mapping ci-dessous permet d’importer dans une table les lignes différentes entre 2 fichiers en entrée :
Déclaration des métadonnées :
Pour cela, il faut dans un premier temps définir 2 métadonnées de type fichier :
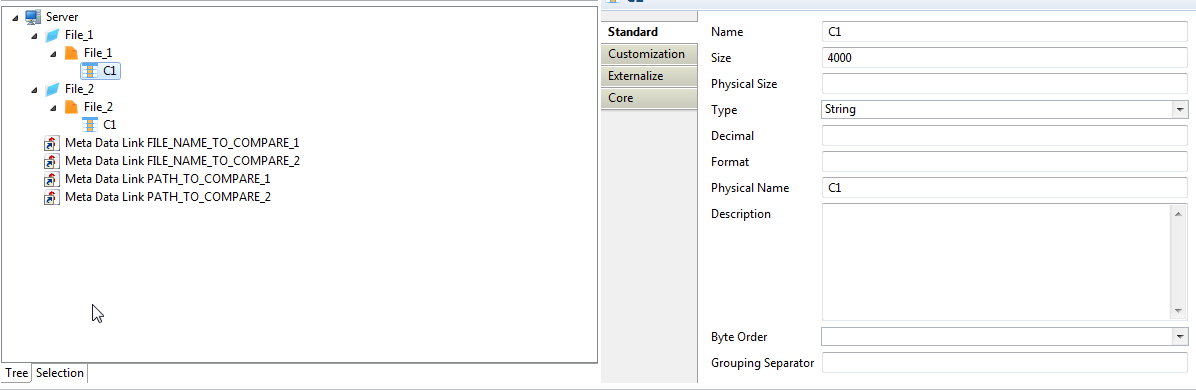
Ces fichiers vont être considérés comme des fichiers plats délimités par le séparateur vide. De cette manière, chaque ligne du fichier sera importée dans une seule et unique colonne en base de données.
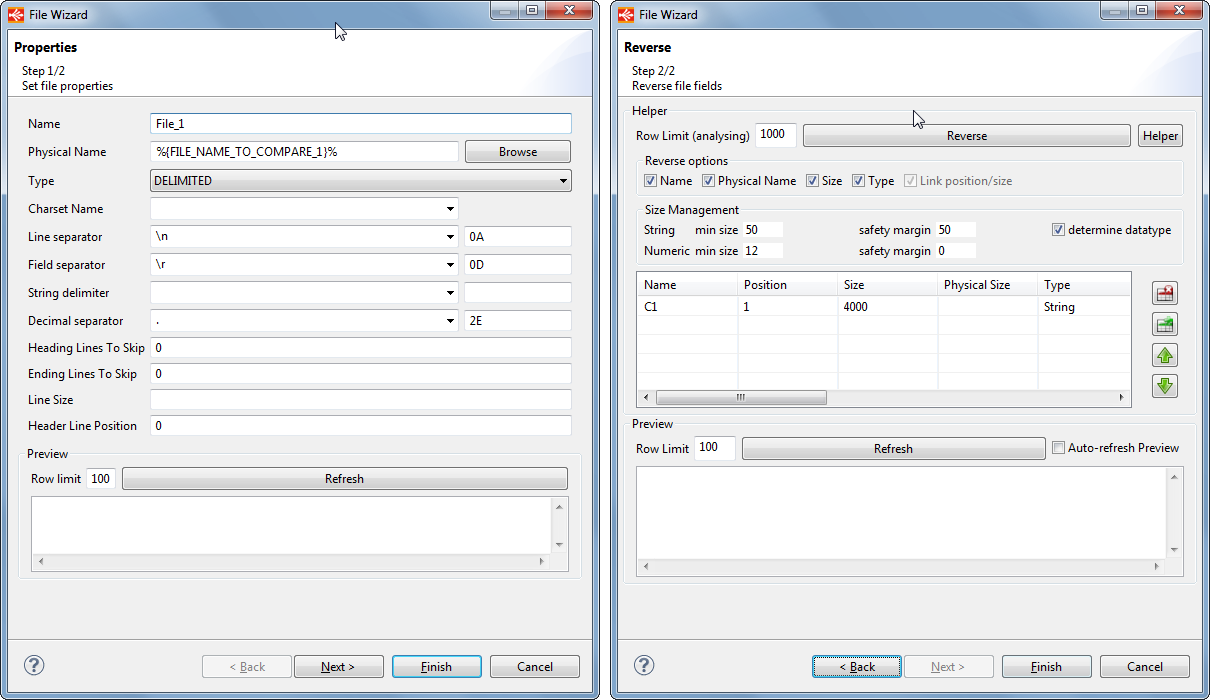
Une fois cela fait, on crée une table COMP_FILE qui va contenir les différences entre les 2 fichiers comparés :
CREATE TABLE [BDD2].[dbo].[COMP_FILE] ( [DIFF] SMALLINT NULL, [FILE_1] NVARCHAR(100) NULL, [FILE_2] NVARCHAR(100) NULL, [CREATED] DATETIME NOT NULL )
Principe du mapping
On reproduit ensuite le mapping ci-dessus qui se définit comme ceci :
- On importe les contenus des 2 fichiers dans 2
stages
- Possibilité de filtrer le contenu des fichiers afin d’exclure certaines lignes de la comparaison
- On compare dans 2 nouveaux stages le contenu des
2 fichiers via 2 requêtes de type EXCEPT afin de vérifier si des lignes sont
différentes et si des lignes ne sont présentes que dans l’un ou l’autre des
fichiers :
- [A] EXCEPT [B]
- [B] EXCEPT [A]
- On fait ensuite un UNION du contenu des 2 derniers stages afin de récupérer l’ensemble des différences entre les 2 fichiers. Cet UNION est ensuite inséré dans la table finale au cas où l’on souhaite consulter les différences trouvées.
La comparaison ne tient pas compte de l’ordre des lignes. Il est possible d’ajouter ce paramètre. Pour cela, il faut remplacer les 2 premiers stage par des tables physique contenant 2 colonnes :
- NUM_LINE INT IDENTITY(1, 1) NOT NULL
- C1 VARCHAR(4000)
Au niveau des EXCEPT, on ajoutera alors le champ NUM_LINE ce qui permettra de tenir compte de la position de la ligne. Attention, dans ce cas, si les fichiers n’ont pas le même nombre de ligne, il y aura un décalage possible et donc de nombreuses lignes ressortiront comme différentes.
Filtrage de certaines lignes
Il a été indiqué précédemment qu’il était possible de filtrer certaines lignes que l’on ne souhaite pas comparer afin, par exemple, de répondre au cas de figure où l’on a un horodatage à l’intérieur du fichier. Pour cela, on va utiliser 2 paramètres :
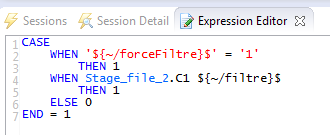
Le premier, ${~/forceFiltre}$’ = ‘1’ est là pour une question de performance, afin que l’on ne teste pas à chaque fois le filtre si ce dernier est vide. Dans ce cas, on aura 1 = 1.
Le second paramètre ${~/filtre}$ contient le vrai filtre. Etant donné que l’on a une seule colonne, il est simple à mettre en place (nous verrons cela au niveau du process exécutant ce mapping).
Process
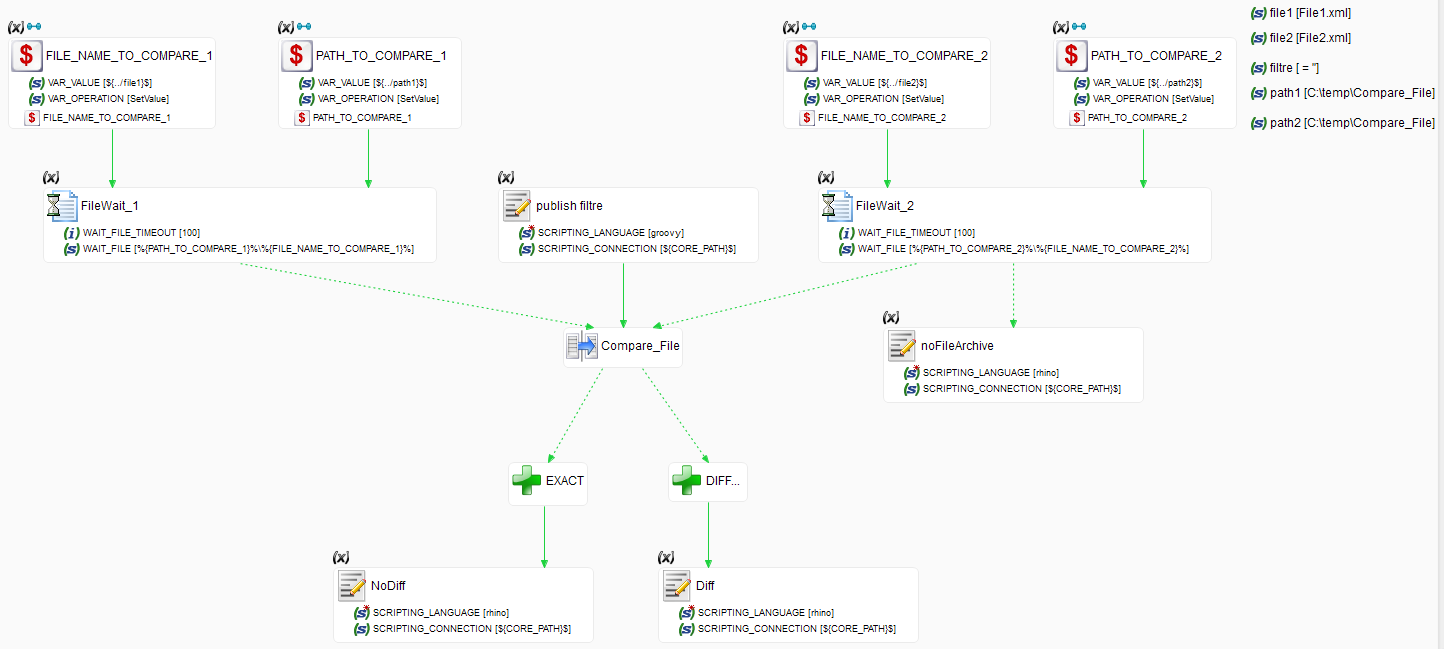
Le process de comparaison de fichier est constitué de :
- Paramètres :
- 2 pour les noms des fichiers
- 2 pour les chemins des fichiers
- 1 pour le filtre de ligne
- 2 File Wait qui servent à vérifier la présence des fichiers
- 4 Variables associées aux paramètres de nom et chemin des fichiers
- Le mapping
- 4 scripts
Note : Nous ne reviendrons pas sur les variables et paramètres associées aux noms et chemins des fichiers qui sont simples à comprendre.
Principe du filtrage
Le paramètre de filtrage à pour valeur par défaut « = » » afin de permettre de déterminer quand on ne souhaite pas exclure de ligne. Ce paramètre est associé au premier script publish filtre.
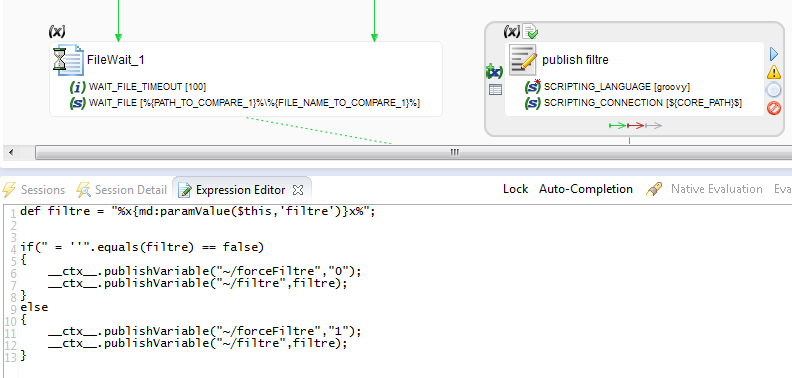
Si le paramètre filtre vaut « = » » alors on publie le paramètre forceFiltre avec pour valeur 1 afin que le bloc CASE WHEN… dans le premier stage (cf ci-dessus) soit toujours vrai. On ne passe donc jamais dans la partie de filtrage des lignes.
Dans tous les autres cas, on publie forceFiltre avec pour valeur 0 ce qui va impliquer que l’on rentre dans la partie du bloc CASE WHEN… qui permet de filtrer des lignes.
On peut par exemple mettre comme filtre LIKE ‘DATE%’ ce qui permettra de filtrer les lignes commençant par DATE. Il serait possible d’ajouter des paramètres filtre1, filtre2, filtre3 suivant le même principe auquel cas, on remplacerait le code par :
CASE WHEN '${~/forceFiltre}$' = '1' THEN 1
WHEN Stage_file_2.C1 ${~/filtre1}$ THEN 1
WHEN Stage_file_2.C1 ${~/filtre2}$ THEN 1
WHEN Stage_file_2.C1 ${~/filtre3}$ THEN 1
ELSE 0
END = 1
Et on modifierait le script en vérifiant qu’au moins un des filtres est différents de « = » ».
FileWait
Les étapes FileWait sont là pour tester l’existence des fichiers à comparer. Si les 2 fichiers sont trouvés, on passe à l’étape suivante qui est le mapping.
Dans le cas contraire, si le fichier 2 n’est pas trouvé, on considère que les fichiers sont différents et on met le paramètre fileDiff à la valeur 1 via le script noFileArchive (on considère en réalité que le fichier 1 existe toujours d’où l’absence de script noFile pour ce fichier).
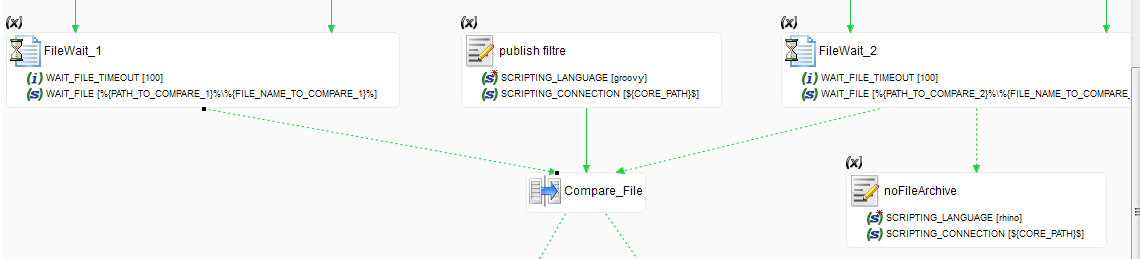
Mapping
Si les 2 fichiers sont présents, on exécute le mapping afin de déterminer s’il y a des différences. Une fois le mapping terminés, on regarde si l’on a inséré des lignes. Si c’est le cas, cela signifie qu’il y avait des différences entre les 2 fichiers comparés.
On publie alors le paramètre fileDiff à la valeur 1. Dans le cas contraire, si aucune ligne n’est insérée, on publie le paramètre fileDiff à la valeur 0 via le script noDiff.
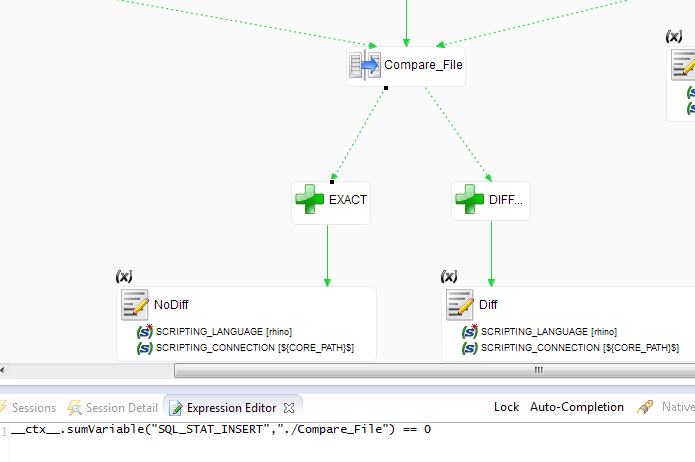
Le paramètre ainsi publié permet de savoir n’importe où dans le process principal si les fichiers sont identiques ou non.